
[Python] Iterable, Iterator 그리고 Generator
0. Index
- 들어가며
- 선수 지식
- 2.1. Iteration: 순회
- 2.2. Abstract Base Class(ABC)
- Iterable과 Iterator
- 3.1. Iterator Protocol
- 3.2. Iterable
- 3.3. Iterator
- 3.4. 나만의 Iterable, Iterator 만들기
- 3.5. Python의 for문 동작방식 추적하기
- 3.6. 상속 관계
- Generator
- 4.1. Generator란?
- 4.2. 생성방법 1: yield
- 4.3. 생성방법 2: Generator comprehension
- 4.4. 상속 관계
- 이들의 존재의 의미를 묻는다
- 마치며
- 자료 출처
- 주의: 이번 포스트는 많이 깁니다. 하지만 유용하고 알차다고 약속드릴 수 있으니 때때로 커피 한 잔 하면서 여유로울 때 읽어주세요.
1. 들어가며
드디어 올 것이 왔다. 다루고 싶다는 열정이 항상 마음 한켠에 자리잡고 있었지만 대충 어림잡아도 양이 방대할 것 같아 쉽사리 도전하지 못했던 바로 그 주제. Iterable, Iterator, Generator… 더 미루지는 못하겠다.
이 주제와 관련된 접하기 쉬운 예를 하나 살펴보자. 내장 함수 sum을 모르는 사람은 없다. list를 받아 (일반적으로) 안의 숫자값들을 더해 반환하는 함수다. 알다시피 여기서 함수의 인자로 꼭 list가 들어가지 않아도 된다. set과 tuple은 물론이고, 심지어 dict도 들어갈 수 있다.
d = {1: 'a', 2: 'b', 3: 'c'}
print(sum(d))
6
이 예제에서는 dict의 key를 상대로 합이 이루어졌다. 여기서 중요한 건 sum 함수가 dict를 인자로 받으면 value가 아닌 key를 상대로 합한다는 것이 아닌, sum 함수가 list뿐 아니라 set, dict 등 다른 자료구조 또한 인자로 받을 수 있다는 것이다. 대체 왜 그럴까? 이 함수를 help 함수의 인자로 줘서 sum 함수의 사용설명서를 출력해보자. 내가 항상 강조하는 헬핑(helping)이다.
print(help(sum))
Help on built-in function sum in module builtins:
sum(iterable, start=0, /)
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
sum 함수의 인자 부분에서 ‘iterable’을 눈여겨보자. 이 문서에 따르면 sum 함수는 인자로 iterable을 받는다. 그렇다는 얘기는 ‘dict, list, set, tuple은 iterable이다’라는 명제가 성립한다. 이후 확인하겠지만 이 명제는 참이며, 이것이 오늘 다루는 주제의 매우 중요한 개념을 관통한다. 대체 iterable은 무엇인가?
오늘은 파이썬에서 객체의 순회와 매우 관련 깊은 Iterable, Iterator, Generator에 대해 알아본다. 먼저 핵심 개념에 이르기 전에 관련된 선수 지식을 먼저 바라본다. 이후 세 개념에 대해 설명하는데 Iterable과 Iterator는 Iterator Protocol이라는 개념으로 묶어 설명하고 그다음 Generator를 살핀다. Generator는 개발자가 사용하기 쉬운 Iterator라고 설명하면 대략 느낌이 맞다. 마지막으로 대관절 이 개념들이 왜 있어야 하고, 어떤 장점이 있는지 밝히는 것으로 포스트를 마친다.
이 주제는 매우 중요하고, 개인적으로 파이썬 초보와 중수를 가르는 기준으로 삼는다. 이 세 개념에 대해 남들에게 문제없이 설명할 수 있는 수준이 되면 최소한의 요구사항을 해결하는 파이썬 프로그램은 짤 수 있다는 뜻으로 해석할 수 있겠다. 그러니 잘 살펴봐야하고 생각보다 재밌기 때문에 기대해도 좋다.
2. 선수 지식
먼저 내용의 바탕이 되는 선수 지식을 살펴보자. 세 개념은 반복문과 관련해서 iteration, 자료구조라는 측면에서 ABC와 매우 깊은 관련이 있다.
2.1. Iteration: 순회
먼저 Iteration, 번역하면 순회라고 할 수 있다. 이 개념은 파이썬만의 개념이 아닌 다른 프로그래밍 언어에서도 통용되는 일반 용어(general term)로서 특히 배열 등의 자료구조를 반복문을 통해 원소 하나씩 인덱싱하는 것을 가리킨다. 다음은 for문을 사용해 list를 순회하는 일반적인 파이썬 코드다.
my_list = [1, 2, 3, 4, 5]
for n in my_list:
print(n)
1
2
3
4
5
이 코드는 ‘for loop를 통해 my_list 라는 리스트(또는 배열)의 원소를 순회했다’고 말할 수 있다.(iterate over my_list with for loop) 반복문은 모든 프로그래밍 언어에서 사용하는 핵심 요소이기 때문에 이해하기 어렵지 않다. 그리고 오늘 소개하는 Iterable, Iterator가 iteration이라는 일반 용어와 iter 라는 접두사를 공유하는 것이 이 개념들이 반복문과 깊은 관련이 있다는 것을 암시하고 있다.
2.2. Abstract Base Class(ABC)
Abstract Base Class(이하 “ABC”)는 객체지향 프로그래밍에서 자료구조의 위계를 세울 때 사용하는 개념으로, 이 개념 또한 파이썬에만 얽매이지 않는 특징을 갖는다. 객체지향을 지원하는 많은 언어들에서 자료구조의 위계를 설계할 때 ABC를 사용하며, 특히 Java에는 추상 클래스를 정의하는 ‘abstract’라는 키워드까지 있을 정도다.
‘추상’의 뜻은 무엇인가? 어렵지 않다. 컴퓨터 공학적으로 ‘추상적’의 의미는 하드웨어에서 멀어진다는 의미이고(파이썬은 garbage collection 등을 직접 하지 않아 C 등의 언어보다는 추상적이다), 소프트웨어 공학적으로 ‘추상적’의 의미는 객체의 구체적인 속성이나 동작을 구현하지 않는다는 의미로 해석하면 대강 맞다.(또는 함수는 구체적인 코드 블락을 이름 뒤로 숨기기 때문에 이것 또한 추상적이다) 이게 핵심이다. 인간은 ‘먹는다’는 행동을 할 수 있는데 정확히 어떤 조건을 만족해서, 어떤 동작을 통해 이 행동을 실현하는지까지의 의미는 포함하고 있지 않다. 문화권마다, 사람마다 구체적인 구현 형태는 다르겠지.
다음은 클래스. 파이썬에서는 모든 것이 클래스다. 오늘 주제와 관련해서는 모든 개별 자료구조는 클래스를 통해 구현된다. 자료구조라는 개념을 좀더 파보자. 파이썬의 기본 내장 자료구조 4개로는 list, tuple, set, dict를 꼽을 수 있다. 처음 배울 때는 이 자료구조의 내부 동작이나 또는 서로 간의 관계 등을 생각하지 않고 배우는데 Iterator.. 등의 개념을 배울 때는 이 내부를 더 들여다볼 필요가 있다. 앞선 4개의 자료구조는 고유한 동작과 특징을 갖는데, 내부적으로 파이썬에서 정의한 특정 추상 자료구조를 상속받고 있다. 파이썬에서 각 추상 자료구조는 자신을 상속받는 클래스가 구현해야 할 메소드를 정의하고 있으며 ‘추상’의 의미에 맞게 구체적인 행동은 지정되어 있지 않다.
파이썬에서는 collections.abc라는 내장모듈에 4개의 핵심 자료구조를 포함한 다른 자료구조들의 뼈대가 되는 추상 자료구조가 클래스로 관리되고 있다. 혹시 파이썬의 문서를 보면서 Sequence, Collection, Mapping이라는 단어를 본 적이 있는지? 특히 Sequence는 파이썬을 조금이라도 진지하게 공부했으면 접해봤음직 하다. 이 자료구조들은 모두 ABC로서 자신들의 메소드를 구현하지 않은 채 선언만 하고 있으며, 클래스로 정의되어 있다.
from collections.abc import Container, Collection, Sequence
print(Container)
print(Collection)
print(Sequence)
<class 'collections.abc.Container'>
<class 'collections.abc.Collection'>
<class 'collections.abc.Sequence'>
그리고 각 추상 자료구조는 자신을 상속받는 클래스가 구현해야 할 메소드를 선언하고 있는데 cls.__abstractmethods__ 라는 속성을 통해 살펴볼 수 있다.
print(Container.__abstractmethods__)
print(Collection.__abstractmethods__)
print(Sequence.__abstractmethods__)
frozenset({'__contains__'})
frozenset({'__len__', '__contains__', '__iter__'})
frozenset({'__len__', '__getitem__'})
이때, 이들을 상속받는 자식 클래스(자료구조)는 각 메소드를 모두 온전히 구현해야 한다. 이제 진짜배기가 나온다. __len__ 이라는 메소드는 len 내장 함수가 호출될 때 실행된다. 이 함수를 통해 우리는 리스트의 길이를 많이 구했다. 이게 가능했던 이유는 내부적으로 list가 Collection 추상 클래스의 __len__ 이라는 추상 메소드를 온전히 구현했기 때문이다. 또한, len 함수는 list뿐 아니라, tuple, set, dict 모두에 적용할 수 있는데 이 자료구조들은 모두 Collection을 상속받는다.
l = [1, 2, 3]
t = (3, 4)
d = {'a': 1, 'b': 2}
s = set()
assert len(l) == 3
assert len(t) == 2
assert len(d) == 2
assert len(s) == 0
assert issubclass(list, Collection)
assert issubclass(tuple, Collection)
assert issubclass(dict, Collection)
assert issubclass(set, Collection)
issubclass 는 내장 함수로, 첫 번째 클래스 인자가 두 번째 클래스 인자의 자식 클래스인지 검증한다. 이게 정말 중요하다. 이게 상속의 힘이기도 하다. 4개의 기본 자료구조는 ‘Collection’이라는 추상 클래스를 상속받고 있다. 개념적으로도, 실제 구현적으로도 말이다. 이때 기억해야 할 것은 각 자료구조마다 메소드의 구체적인 구현 내용은 다를 것이라는 것이다. 사실 당연한 거다. 자료구조의 성격이 서로 다른데 어떻게 코드가 정확히 같겠는가. 하지만 우리가 예상하는 행동은 예측범위 안에서 하고 있다. 이게 곧 객체지향에서 말하는 다형성(Polymorphism)이기도 하다.
ABC에 대해 길게 여기까지 온 이유가 이제 나온다. Iterable, Iterator, Generator는 개념이기도 하며 또한 ABC에 정의되어 있는 추상 클래스이기도 하다. 이 셋은 추상 클래스로서 따라서 기본 자료구조들이 상속받기도 하고, 또는 상속받지 않기도 하다.
from collections import Iterable, Iterator, Generator
abs = (Iterable, Iterator, Generator)
basic = (list, tuple, set, dict)
for b in basic:
for a in abs:
print(f'{b.__name__}는 {a.__name__}를 상속 받나요?', issubclass(b, a))
list는 Iterable를 상속 받나요? True
list는 Iterator를 상속 받나요? False
list는 Generator를 상속 받나요? False
tuple는 Iterable를 상속 받나요? True
tuple는 Iterator를 상속 받나요? False
tuple는 Generator를 상속 받나요? False
set는 Iterable를 상속 받나요? True
set는 Iterator를 상속 받나요? False
set는 Generator를 상속 받나요? False
dict는 Iterable를 상속 받나요? True
dict는 Iterator를 상속 받나요? False
dict는 Generator를 상속 받나요? False
위에서 흥미로운 것은 기본 자료구조들은 모두 Iterable을 상속받고, Generator, Iterator는 상속받지 않는다는 것이다. 특히 Iterable을 모두 상속받는 것을 통해 첫 장에서 이야기했던, sum의 인자가 iterable인 이유를 알 수 있다. list, tuple, set, dict 모두 iterable이기 때문에(Iterable 추상 클래스를 상속받기 때문에) sum 함수의 인자로 사용할 수 있었던 것이다.
다음 장에서부터는 각 추상클래스에 대해 구체적으로 알아보고 그들의 관계에 대해서도 심도 있게 살펴봐야 한다.
3. Iterable과 Iterator
앞서 Iterable과 Iterator는 ‘collections.abc’ 내장 모듈에 정의되어 있는 추상 클래스라는 것을 살펴봤다. 또 우리는 이 개념이 반복문과 매우 큰 관련이 있음을 안다. 그래서 이제 각각에 대해 개념적으로, 또 기술적으로 어떤 특징이 있는지 살펴볼 생각이다. 근데 이들은 같은 접두사를 공유하는 것과 같이, 묶어서 설명할 수 있다.
두 클래스는 파이썬의 Iterator Protocol이라는 개념 속에서 정의되는 한 쌍이다. 그래서 먼저 Iterator Protocol이 뭔지 대략적으로 살피고 Iterable, Iterator에 대해 각각 살핀다. 그리고 이 둘을 이해할 수 있으면 이제 파이썬에서 for 문이 정확히 어떤 식으로 동작하는지 더 생생하게 이해할 수 있다. 이 장의 마지막에서는 이 둘의 상속 관계를 코드로, 그리고 개념적으로도 확인한다.
3.1. Iterator Protocol
이번 절에서는 Iterator Protocol을 개념적으로 먼저 설명하자. 구체적인 구현은 각 개념을 설명할 때 살펴본다. 괜히 어려워 보이는 ‘protocol’이라는 단어에 집중할 필요가 있다. ‘protocol’은 여기서는 원 뜻에 충실하게 ‘규칙’, ‘규약’이라는 의미로 보면 정확히 맞다.
Iterator Protocol은 Iterable과 Iterator를 개념적으로, 또 실제적으로 구현하는 규칙을 정의한다. 쉽게 말하면, Iterable과 Iterator를 만드는 방법이라고 생각해도 된다. 이 프로토콜이 요구하는 대로 우리가 사용하는 모든 Iterable과 Iterator 클래스가 구현되어 있다. 즉, 앞서 살펴봤듯이 list, dict 등은 내부적으로 Iterator Protocol에서 정의한 Iterable 구현 요구사항이 모두 충족되어 있기 때문에 Iterable이다. 이 말은 이 프로토콜을 준수한 클래스를 만든다면, (dict, list 등 미리 정의된 것이 아닌) 우리만의 커스터마이즈한 Iterable과 Iterator를 만들 수 있다는 뜻이기도 하다. 이번 장에서 해볼 것이다.
3.2. Iterable
이제 Iterable과 Iterator의 보다 구체적인 내용을 살펴보자. 먼저 Iterable. Iterable은 개념적으로 이해하기에는 매우 쉽다. ‘순회하다’의 ‘Iterate’에 ‘가능한’이라는 의미를 갖는 ‘-able’ 접미사가 붙어서 ‘순회 가능한’으로 이해할 수 있다. 즉, Iterable은 순회할 수 있는 모든 객체를 가리킨다. 다른 말로 하면 파이썬에서 for 문의 in 키워드 뒤에 올 수 있는 모든 값은 Iterable이다. 그러면 list, tuple, set, dict는 말할 것도 없고 문자열, 파일 등도 Iterable이라고 할 수 있다.
s = 'abc'
for c in s:
print(c)
print()
file_name = 'any_textfile_path'
for line in open(file_name):
print(line)
a
b
c
---
... 파일의 내용마다 다름. 이하 생략
예시에서 보듯 파이썬에서는 문자열과 파일 객체를 모두 for 문에서 사용할 수 있다. 그럼 정말 이들은 Iterable인가.
import io
assert issubclass(str, Iterable)
assert issubclass(io.TextIOWrapper, Iterable)
모두 AssertionError 에러 없이 잘 작동한다. 즉, 문자열과 파일 클래스는 Iterable이다. 이때 두 번째 검정식에서 io.TextIOWrapper가 낯설지 모르겠다. 우리가 open 함수로 파일을 열면 해당 파일은 사실 저 클래스의 인스턴스가 된다. ‘wrapper’라는 단어를 보아하니 실제 시스템에서 여닫는 파일을 파이썬에서 사용할 수 있게 감싸는 역할을 하는 것 같다. 이 wrapper를 통해 파일 인스턴스를 for 문에서 쓸 수 있었다.
즉, 개념적으로 파이썬에서 for 문에 넣을 수 있는 모든 객체는 Iterable이라고 말할 수 있다.
그러면 Iterator protocol을 통해 Iterable을 만들려면 어떻게 해야 할까? 아까 구현해야 할 추상메소드를 확인했던 속성으로 확인해보자.
print(Iterable.__abstractmethods__)
frozenset({'__iter__'})
즉, Iterable를 상속받는 클래스는, 즉 클래스가 Iterable이기 위해서는:
- __iter__ 추상메소드를 실제로 구현해야 하며 이 메소드는 호출될 때마다 새로운 Iterator를 반환해야 한다.
자료구조나 클래스가 Iterable이기 위해서는 이 조건만 만족하면 된다. 클래스에 __iter__ 메소드가 구현되었으면 해당 객체에 iter 라는 내장 함수를 적용해 Iterator를 생성할 수 있다.
그러면 앞서 Iterable이라고 확인했던 자료구조들에 iter 내장함수를 사용하면 진짜 Iterator가 반환되는지 확인해보자.
l = [1, 2, 3]
t = (3, 4)
d = {'a': 1, 'b': 2}
s = set()
r = range(10)
print(iter(l))
print(iter(t))
print(iter(d))
print(iter(s))
print(iter(r))
<list_iterator object at 0x7f08026e4fd0>
<tuple_iterator object at 0x7f08026e49e8>
<dict_keyiterator object at 0x7f0802721228>
<set_iterator object at 0x7f08031b9480>
<range_iterator object at 0x7f0801dc6390>
오호, 실제로 Iterable을 iter 내장 함수의 인자로 주니 각 자료구조의 Iterator가 반환되었다. 각 자료구조는 내부적으로 __iter__ 메소드를 구현하고 있다고 생각해도 된다. 또 생각해볼 점은 우리가 뻔질나게 썼던 range가 Iterable이라는 것이다. for 문에서 쓸 수 있으니 당연하다. 파이썬을 처음 배울 때는 이것을 몰랐는데 이제는 어떤 의미인지 안다.
이제는 Iterator가 정확히 무엇인지 파악해보자.
3.3. Iterator
앞서 Iterable의 기술적 요구사항은 __iter__ 메소드를 구현해서 인스턴스에 iter 내장 함수를 적용했을 때 Iterator를 반환하는 것이라고 했다. 그렇다면 이제는 Iterator가 뭔지 살펴보자.
먼저 개념적으로 살펴보자. ‘Iterable은 for 문에 넣을 수 있는 모든 값’으로 정의하면 되지만 Iterator는 조금 더 까다롭다. Iterator는 상태를 유지하며 반환할 수 있는 마지막 값까지 원소를 필요할 때마다 하나씩 반환하는 것이라고 생각하면 된다. 확실히 말이 좀더 어렵다. 하지만 언제나 그렇듯 분할정복을 통하면 만사형통이다. ‘반환할 수 있는 마지막 값까지 원소를 하나씩 반환한다’의 의미는 가령 list에서 값을 하나씩 반환하는 것과 동작이 같다.
l = [1, 2, 3, 4, 5]
for n in l:
print(n)
1
2
3
4
5
for 문을 통해서 각 값을 하나씩 반환했다. 그리고 끝에 다다르면(여기서는 5) 더 이상 반환하지 않는다. 여기까지는 Iterable과 다르지 않는데 ‘상태를 갖는다’가 중요하다.
각 Iterator는 상태를 갖는다. 이 말이 중요하다. Iterable에 iter 함수를 쓸 때마다 새로운 이터레이터가 생성된다. 이때 각 Iterator는 서로 다른 상태를 유지하고 있다. 다시 말해 한 Iterator의 동작이 다른 Iterator의 동작에 영향을 미치지 않는다.
assert iter(l) != iter(l)
좋아, 그러면 각 Iterator가 관리하는 ‘상태’란 무엇인가? 많은 사항이 있겠지만, 여기서는 각 Iterator가 순회하고 있는 위치라고 생각하면 된다. for 문을 통해서는 무조건 Iterable의 끝값까지 모두 살펴보지만, 뒤에서 확인가능하듯이 Iterator는 필요에 따라 한 번에 한 값씩만 반환할 수 있다.
즉, 한 Iterable에 대한(가령 [1, 2, 3, 4]) 서로 다른 Iterator를 만들어서 한 Iterator는 2까지 반환해서 다음 반환값이 3에 머무르게 하고, 다른 Iterator는 4까지 모두 반환해서 더 이상 반환할 값이 없도록 할 수 있다는 것이다. 두 Iterator는 서로 다른 상태값을 유지, 관리하는 완전히 다른 객체다. 비록 같은 Iterable에서 생성됐지만. 이게 개념적 핵심이다.
Iterator는 iter 함수의 인자로 Iterable을 적용해 반환된 객체로, 값을 하나씩 반환하며 그 상태값을 유지, 관리하는 객체라고 개념적으로 이해할 수 있었다. 그러면 이번엔 Iterator를 어떻게 구현하는지 살펴보자.
Iterator protocol을 통해 Iterator를 만들려면 어떻게 해야 할까? 아까처럼 __abstractmethods__ 속성을 통해 살펴보자.
print(Iterator.__abstractmethods__)
frozenset({'__next__'})
클래스가 Iterator이기 위한 필수적인 메소드는 __next__인 것 같다.
어떤 클래스가 Iterator이기 위해서는 다음과 같은 조건을 만족해야 한다:
- 클래스는 __iter__ 를 구현하되 자기 자신(self)을 반환해야 한다.
- 클래스는 __next__ 메소드를 구현해서 Iterator를 next 내장 함수의 인자로 줬을 때 다음에 반환할 값을 정의해야 한다.
- Iterator가 더 이상 반환할 값이 없는 경우는 __next__ 메소드에서 StopIteration 예외를 일으키도록 한다.
위의 세 가지의 요구사항을 모두 구현했을 때 그 클래스는 Iterator라고 할 수 있다.
이때 __next__ 메소드를 주목할 필요가 있다. 앞서 Iterator는 끝에 다다를 때까지 원소를 하나씩 반환하는 특징이 있다고 했다. next 내장 함수는 인자가 되는 Iterator의 다음 인자를 반환하고 위치를 다음으로 옮기는 기능을 한다. for문은 Iterator를 강제적으로 현재 위치에서(첫 원소가 아닐 수 있다) 끝 원소까지 모두 반환하게 한다고 이해할 수 있다. 실제로 next 함수를 써보자.
iterator = iter([1, 2, 3, 4, 5])
print(next(iterator))
print(next(iterator))
print(next(iterator))
1
2
3
평범한 list에 iter 함수를 써서 반환된 Iterator를 iterator 라는 변수에 할당했다. 이 Iterator는 내부에 __next__ 메소드가 구현되어 있기 때문에 next 내장 함수가 호출될 때마다 원소를 하나씩 반환한다. 위에서는 next를 세 번 호출했기 때문에 세 번째 값까지 호출됐다. 이 상태에서 iterator는 현재까지 값을 반환한 위치를 기억하고 있기 때문에 다음에 next를 호출하면 네 번째 값(4)이 반환되리라고 예상할 수 있다.
for n in iterator:
print(n)
4
5
이미 세 번의 next 함수 호출을 통해 3까지의 값이 반환되었기 때문에 남은 반환 횟수는 두 번이다. for 문을 통해서 네 번째 값부터 끝까지 출력할 수 있었다. iterator가 순회 상태를 관리하기 때문에 for문에서 다시 1부터 출력되는 것이 아닌 현재 상태값 4부터 출력하고 있다.
iterator는 일회용 깡통과 같아서 값을 모두 사용했다면 재사용할 수 없다. iterator 는 마지막 원소까지 모두 반환했고 이후에 next를 통해 강제적으로 반환을 요구하면 내장 예외인 StopIteration이 반환된다.
next(iterator)
----> 1 next(iterator)
StopIteration:
정리하면 Iterator는 Iterable에 iter 내장 함수를 적용해 반환되는 객체로서 next 함수를 통해 값을 한 번에 한 번씩 반환하는 특징이 있다. 내부적으로 현재까지의 반환 상태를 관리하고 조건에서 정의한 마지막까지 반환하면 더 사용할 수 없으며 StopIteration 예외를 일으킨다.
이게 Iterator의 주요 특징이다. 다음에는 이번에 학습한 Iterable과 Iterator에 더 익숙해지기 위해 나만의 커스터마이즈한 Iterable과 Iterator를 만들어보자.
3.4. 나만의 Iterable, Iterator 만들기
앞선 절에서 Iterable, Iterator의 주요 특징과 구현을 위한 요구사항을 살펴봤다. 즉 Iterator Protocol을 정리했으며, 우리는 이 프로토콜을 준수하는 클래스를 만들면 나만의 Iterable, Iterator를 만들 수 있다고도 했다. 정말 그런지 확인해보자. 이번 절에서는 이 프로토콜을 준수한 나만의 Iterable, Iterator를 만들어서 활용해보며, 프로토콜을 온전히 구현했을 때 for 문에서도 문제없이 사용할 수 있다는 것까지 증명해본다.
예제는 1부터 100까지의 정수를 랜덤으로 n개 반환하는 Iterable, Iterator를 만들어보자. 이때 n개는 Iterable의 생성 인자로 받으면 되겠다. 먼저 Iterable부터 만들어보자.
프로토콜에서 Iterable의 요구사항은 간단하다. __iter__ 메소드가 매번 새로운 Iterator를 반환하도록 할 것. 바로 코드로 옮긴다.
class RandomIntIterable:
def __init__(self, n):
self.n = n
def __iter__(self):
return RandomIntIterator(self.n)
RandomIntIterable 는 Iterator가 반환할 임의의 정수 개수를 의미하는 n 을 받는다. 그리고 값을 인스턴스의 속성으로 지정한다. __iter__ 메소드는 밑에서 정의할 RandomIntIterator 를 반환하는데 속성으로 할당한 n을 Iterator 생성자의 인자로 준다.
다음은 Iterator를 정의하자.
from random import randint
class RandomIntIterator:
def __init__(self, n):
self.count = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.count < self.n:
self.count += 1
return randint(1, 100)
else:
raise StopIteration
- RandomIntIterator 를 정의했다. 생성자 메소드에서 개수 n을 받아 인스턴스 속성으로 할당한다. 현재까지 몇 개의 정수를 반환했는지 저장하는 count 변수도 0으로 초기화한다. 이 변수를
상태라고 할 수 있다. - 프로토콜에서 요구하는 대로 __iter__ 메소드는 자기 자신(self)을 반환한다.
- __next__ 메소드가 핵심이다. 이 메소드는 지금까지 반환한 정수의 개수가 n개 이하일 때는 랜덤 정수를 반환한다. n개 만든 이상 요구사항은 끝났기 때문에 그 이후부터는 StopIteration exception을 반환한다.(raise)
실제로 동작하는지 사용해보자.
able = RandomIntIterable(3)
tor1 = iter(able)
tor2 = iter(able)
assert tor1 != tor2
먼저 3개의 랜덤 정수를 반환할 예정인 RandomIntIterable 의 인스턴스를 생성했다. 그리고 iter 함수를 통해 만든 RandomIntIterator를 두 개 만들어 각각 할당한다. 각 iter 함수는 호출될 때마다 새로운 Iterator를 만들어야 하기 때문에 두 Iterator는 서로 다르다.
# 1. Iterator에 iter 함수 적용
assert tor1 is iter(tor1)
# 2. next를 통해 각 값을 반환
print(next(tor1))
print(next(tor1))
print(next(tor1))
print(next(tor1))
69
50
99
StopIteration:
tor1 은 RandomIntIterator 의 인스턴스로 다음과 같이 Iterator protocol을 온전히 구현했다:
- iter 함수의 호출 결과로 새로운 Iterator가 아닌 자기 자신을 반환했으며
- next 함수를 통해 정해진 개수만큼 랜덤 정수를 반환했다. 애초에 반환할 개수를 세 개로 정의했기 때문에 네 번째 next 호출부터는 StopIteration exception이 반환됐음을 알 수 있다.
마지막으로 우리가 만든 Iterable, Iterator를 for 문에서 사용할 수 있는지 확인해보자.
for n in tor2:
print(n)
89
100
64
아까 정의한 tor2 를 for문에 넣으니 정확히 랜덤 정수가 3개 반환됐다. tor2 는 Iterator로서, 수없이 확인했듯이 for문에는 Iterable도 들어갈 수 있어야 한다.
for n in RandomIntIterable(5):
print(n)
37
35
35
97
56
정말 문제없이 동작한다! 이렇게 Iterator protocol을 준수해 Iterator와 Iterable을 정의하면 둘 모두를 for문에서 다른 내장 자료구조처럼 문제없이 사용할 수 있음을 확인했다.
3.5. Python의 for문 동작방식 추적하기
지금까지의 내용을 바탕으로 파이썬에서의 for문이 어떻게 동작하는지 살펴보자. 다음은 해석 대상인 간단한 for문이다.
for n in 1, 2, 3, 4, 5:
print(n)
1
2
3
4
5
1부터 5까지 출력하는 매우 간단한 활용이다. ‘in’ 키워드 뒤에 []나 ()가 없다고 놀라지 말자. 파이썬에서 두 개 이상의 값을 괄호 없이 쓰면 tuple로 인식한다. 파이썬 인터프리터에 ‘1, 2’라고 입력해보라.
자, 우리는 지금까지 저런 식이 내부적으로 어떻게 돌아가는지 전혀 신경쓰지 않았다. 하지만 Iterator protocol을 익히고 이 프로토콜을 준수하는 나만의 Iterator를 만든 지금, 저 식이 어떤 단계를 거쳐 진행되는지 추적할 수 있다:
- ‘in’ 뒤의 Iterable(또는 Iterator)에 iter 내장 함수를 써서 Iterator를 얻는다
- Iterable에 iter를 쓰면 새로운 Iterator가 반환되고, Iterator에 iter를 쓰면 자기 자신이 반환된다는 것을 확인했다. for문에 순회 가능한 자료구조를 입력하면 자기 자신이 쓰이는 것이 아니라 일회용 Iterator를 만들어 쓰게 된다.
- 반환된 Iterator에 next 함수를 써서 한 번씩 값을 얻어낸다
- 말 그대로다. 우리는 Iterator에 next 함수를 쓰면 값이 하나씩 튀어나옴을 안다. 값이 나오는만큼 반복문이 돌아가게 된다.
- next 함수의 결과로 StopIteration 예외 처리가 반환되면 반복문을 종료한다
- 무한반복문을 만들 수도 있지만 range 등의 일반적인 활용에서는 반복문의 끝을 상정한다. Iterator가 마지막 값을 뱉어내면 Iterator는 다음 next 함수에서 예외를 일으키기 때문에 반복문을 내부적으로 종료한다.
아하, 이제 좀 알겠다. 파이썬의 for문은 내부적으로 위와 같은 과정을 거치기 때문에 타 언어의 for문과 동작 과정이 다르다. 보통 타 언어는 정해진 조건을 만족하는 한 단순히 반복할 뿐인데 파이썬은 위와 같은 과정이 숨겨져 있다.
3.6. 상속 관계
Iterable과 Iterator는 collections.abc에 있는 다른 많은 자료구조처럼 다른 자료구조를 위한 추상 데이터 타입(Abstract Data Type, ADT)이다. 앞서 파이썬의 기본 자료구조들이 이 안의 자료구조들을 상속한다는 것을 확인했는데, 얼핏 넘어갔지만 ADT 사이에도 상속관계가 성립한다. 구체적인 내용은 이 포스트의 취지가 아니기에 넘어가는데 중요한 것은 Iterable과 Iterator 사이에도 상속관계가 성립한다는 것이다. 이번 절에서는 이 둘의 상속관계를 개념적으로, 또 실제 파이썬 코드를 통해서 확인해본다.
먼저 개념적으로 살펴보자. 상속관계를 확인할 때 자주 사용하는 ‘a는 b다’ 논리를 사용해보자. 가령 자동차라는 추상 클래스를 만들고 이를 상속하는 트럭, SUV, 트랜스포머라는 보다 구체적인 자식 클래스를 만들자. 당연히 이들은 자동차 추상 클래스를 상속해서 무릇 자동차라면 가져야 할 속성과 행동을 자신의 방법으로 정의할 것이다. 이때 두 가지 명제를 살펴보자.
- 트럭은 자동차다.
- 자동차는 트럭이다.
두 명제 중 첫 번째 명제만이 참이다. 더 설명이 필요없을 정도로 납득이 가는 논리다. 이런 논리가 성립할 때, 즉 A는 B다라는 논리가 성립할 때 객체지향의 관점에서는 ‘A는 B를 상속받는다’, ‘또는 B는 A의 부모 클래스다’라는 논리가 참이 된다.
이 논리를 Iterable과 Iterator에 적용해보자. 두 가지 명제를 만들어볼 수 있을 것이다.
- Iterable은 Iterator다.
- Iterator는 Iterable이다.
즉, 우리의 질문은 두 명제 중 어떤 것이 참이냐 하는 것이다. 두 명제가 모두 참일 수 있고, 모두 거짓일 수도 있으며, 하나만이 진리를 담을 수도 있다. 이제 한 명제씩 살펴보자.
- Iterable은 Iterator인가?
Iterable이 Iterator이기 위해서는 Iterator의 모든 조건을 준수해야 한다. Iterator이기 위한 조건이 비교적으로 복잡했는데 먼저 iter 함수의 인자로 넣었을 때 자기 자신을 반환하고, next로 현재 위치를 유지하며 값을 반환해야 한다가 필수요건이다. 그런데 Iterable은 이 조건을 만족하지 못한다. 단적인 예로 아무 list나 next 함수의 인자로 주면 에러가 발생한다.
따라서 Iterable은 Iterator가 아니다, 즉 Iterable은 Iterator를 상속받지 않는다.
- Iterator는 Iterable인가?
반대로 Iterator가 Iterable이기 위해서는 Iterable의 조건을 준수해야 한다. Iterable이기 위한 조건은 상대적으로 느슨했다. iter 함수의 인자가 되었을 때 Iterator를 반환할 것. 이때 Iterator는 이 조건을 만족한다. Iterator에 iter 함수를 쓰면 자기 자신(곧 Iterator)을 반환함을 우리는 안다. 비록 새로운 Iterator를 반환하지는 않지만 이는 자식 클래스의 다형성으로 이해할 수 있다. 즉, Iterator는 Iterable로, 다시 말해 Iterator는 Iterable를 상속받는다.
이 명제는 파이썬을 조금만 이해해도 바로 확인할 수 있는데 맨 처음 장에서 sum 함수의 설명서를 출력하면 첫 인자가 ‘iterable’이라는 것을 확인했다. 이때 sum 함수의 인자로 가령 list의 Iterator를 넣어도 문제없이 값이 반환된다.
l = [1, 2, 3, 4, 5]
print(sum(iter(l)))
15
iter(l) 의 반환값은 list iterator다. 이 Iterator가 sum 함수의 인자가 될 수 있다는 것은 곧 Iterator가 Iterable임을 정확히 가리킨다.
다음으로 파이썬 코드로 살펴보자. issubclass 함수를 써서 Iterable과 Iterator의 관계를 직접적으로 살펴보면 되겠다.
print(issubclass(Iterable, Iterator))
print(issubclass(Iterator, Iterable))
False
True
이보다 더 명확할 수는 없다. 결론적으로, Iterator는 Iterable이며, Iterator는 Iterable의 자식 클래스이고, Iterable을 상속받는다.
4. Generator
앞선 장에서 다소 긴 내용으로 Iterator와 Iterable에 대해 살펴봤다. 이제는 Generator가 무엇인지 알아보자. 경험칙으로 봤을 때 일반적인 프로그래밍을 할 때는 Iterable과 Iterator를 훨씬 더 많이 쓰는 것 같은데(for문 등 안에서), 직접 만들어 사용할 때는 커스텀 Iterable, Iterator를 만들기보다는 Generator를 훨씬 더 많이 사용하는 것 같다. 따라서 이 내용도 주의깊게 살펴봐야 한다.
4.1. Generator란?
이에 대해 직접 언급하기 전에 앞서 만들었던 나만의 Iterable, Iterator 예제를 살펴보자. 아마 받은 개수만큼 랜덤 정수를 반환하는 역할을 했던 것으로 기억한다. 이후 Generator 예제도 이것을 구현하려고 한다.
이때 ‘Iterable과 Iterator의 특징(다음 장에서 볼 장점)을 유지하면서 Iterable과 Iterator를 만들 때 준수해야 하는 Iterator protocol을 쉽게 우회할 수 없을까’가 우리가 집중해야 할 핵심이다. 앞선 두 클래스 코드를 가져오면 다음과 같다.
from random import randint
class RandomIntIterable:
def __init__(self, n):
self.n = n
def __iter__(self):
return RandomIntIterator(self.n)
class RandomIntIterator:
def __init__(self, n):
self.count = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.count < self.n:
self.count += 1
return randint(1, 100)
else:
raise StopIteration
나만의 Iterable과 Iterator를 만들기 위해서는 다음과 같이 Iterator protocol을 준수해서 클래스를 완성해야 한다. 이런 클래스의 수요가 충분하다고 할 때(장점은 다음 장에서 살펴볼 것이다), 프로토콜을 준수해 만드는 문법이(비용이) 요구사항에 비해 조금 복잡해보인다. 위의 예제에서 우리가 만들고자 하는 것은 단순히 상태를 유지하면서 입력한 개수만큼 랜덤 정수를 만드는 기능인데 이를 위해 코드가 적잖이 사용됐고 두 개의 클래스를 작성해야 했다.
Generator는 나만의 Iterable, Iterator 기능을 만들되, 생성 문법을 기존보다 단순화한 개념 또는 클래스라고 할 수 있다. Generator는 앞선 두 클래스와 마찬가지로 collections.abc에 저장되어 있다.
from collections import Generator
print(Generator)
<class 'collections.abc.Generator'>
Generator를 만드는 방법은 크게 두 가지인데 이 둘 모두 중요하기에 잘 살펴보도록 하자.
4.2. 생성방법 1: yield
먼저 대표적인 방법으로 Generator 만을 위한 yield 문을 사용하는 방법을 살펴보자. 문법 자체는 어렵지 않기 때문에 구현했던 랜덤 정수 추출 기능을 yield를 사용해서 바로 만들어보겠다.
from random import randint
def random_number_generator(n):
count = 0
while count < n:
yield randint(1, 100)
count += 1
‘yield’ 문을 활용한 기초적인 Generator 활용 예제다. 사용해보기 전에, Iterator를 직접 구현했을 때와 대비되는 Generator의 특징을 살펴보면 다음과 같다.
- 클래스가 아닌 함수로 정의한다.
- 프로토콜처럼 Iterable와 Iterator의 두 요소를 분리하지 않고 한 요소에 담을 수 있다.
- 호출될 때마다 한 번씩 반환할 값을 반환하는 키워드가 ‘yield’이며, 이는 함수가 아니다. 즉 return 문처럼
()를 사용하지 않는다.
이상의 대표적인 특징이 있다. 이제 이를 직접 만들어서 활용해보자. 랜덤 정수를 5개 반환하는 Generator를 만들어보자.
g = random_number_generator(5)
print(g)
<generator object random_number_generator at 0x7f0801e15e08>
함수를 호출해 generator 객체(object)를 만들었다. 이때 객체라는 것은 함수의 반환값이 상태값을 유지하는 Generator 클래스의 인스턴스(instance)라는 것을 암시한다. Generator는 Iterable, Iterator 생성 문법을 간략화한 개념 및 구현이기 때문에 그 내부과정이 직관적으로 보이지는 않지만(추상화되었기 때문에), 함수의 호출 결과가 결국은 Iterator protocol을 준수하는 개체를 반환한다고 이해하면 무난하다.
생성된 Generator를 사용해보자.
print(next(g))
print(next(g))
print(next(g))
72
90
3
예상했던 대로 next 함수의 인자에 넣어서 하나의 값씩 반환할 수 있다. 총 5개의 값을 반환할텐데 이미 3개를 반환했으므로 남은 반환 횟수는 2번이 된다.
print(next(g))
print(next(g))
print(next(g))
48
34
----> 3 print(next(g))
StopIteration:
# 총 5번의 호출 이후 StopIteration이 반환됐다.
예상했겠지만 다른 generator object를 만들어서 for문에 넣어도 문제없이 동작한다. 결국 아까보다 훨씬 간략화한 문법으로 정확히 같은 기능을 구현할 수 있었다. yield statement를 정말 많이 써보지는 않았는데, 알고리즘 문제 등에서 일반 list를 통한 연산 대신에 때로는 Generator를 사용해서 비약적인 성능 향상을 경험하기도 했다. 결국 이는 Iterator, Iterable의 장점과도 연결되는데, 이는 언급했듯이 다음 장에서 살펴볼 것이다.
다음 절에서는 yield를 사용한 방법보다 더 짧고 쉬운 문법을 토대로 Generator를 만들어본다.
4.3. 생성방법 2: Generator comprehension
Generator를 만드는 방법은 ‘yield’ 키워드를 쓰는 것 이외에 하나 더 있다. 바로 Generator comprehension을 사용하는 방법이다. list comprehension에 대해 다룬 지난 포스트에서 list comprehension식을 list뿐 아니라 set, tuple, dict 등으로 확장할 수 있음을 확인했다. 각 자료구조는 자신을 생성하는 기호([], {})를 사용해서 list, dict 등을 만드는데 예외가 있었다. ()를 사용해서 comprehension을 만들면 tuple이 생성되지 않고 다음과 같은 결과가 나온다.
print((n for n in range(3)))
<generator object <genexpr> at 0x7f0801c6f620>
[]를 사용해 만든 comprehension은 list를 만들었다. 그러면 ()를 사용하면 tuple이 반환되리라 무난하게 예상할 수 있다. 그런데 예상과는 정반대로 ()를 사용하면 tuple이 아닌 ‘generator object’가 생성됐다. 즉 Generator가 생성된 것이다! 뒤에 있는 ‘<genexpr>‘은 ‘generator expression’의 약자로 generator comprehension은 generator expression이라고도 부른다. 그런데 보통 list comprehension을 list expression이라고 하지는 않는 것 같다. generator의 경우는 편한 용어를 선택적으로 사용하면 된다.
즉, list comprehension의 문법을 사용하되 식을 닫는 괄호를 ()를 사용하는 방법이 generator를 생성하는 두 번째 방법이며, 이를 Generator comprehension(또는 generator expression)이라고 한다. 우리의 예제를 generator comprehension을 사용해서 재창조해보자.
from random import randint
g = (randint(1, 100) for _ in range(5))
놀랍도록 단순하다. 한 줄로 나온다. 이런 단순함이 곧 list comprehension의 장점이었다. list comprhension을 통해 list를 손쉽고 짧게 만들 수 있었던 것처럼 generator expression을 통해 Generator를 쉽게 만들 수 있었다. 잘 만들었는지 사용해보자.
for n in g:
print(n)
96
34
71
13
33
Iterable, Iterator와 같이, 그리고 ‘yield’를 통해 만든 Generator와 같이 요구사항대로 동작한다. 생성한 Generator(g)에 next 함수를 썼어도 물론 문제없이 동작한다. list comprehension을 안다면 문법이 동일해서 더 많은 설명이 필요하지도 않다.
그러면 다음과 같은 질문을 던질 수 있다. Iterable, Iterator, Generator에서 Generator만 쓰면 되는가? 또 Generator를 사용한다고 할 때, yield를 사용하는 대신 Generator expression을 사용하는 방법이 무조건 옳은 것인가?
개념을 한 장씩 설명하면서 expression을 사용하는 방법이 더 짧고, 그래서 더 좋다는 식으로만 이야기했는데 정답은 ‘상황에 따라 다르다’이다. 사용하기 더 쉬워지고 간략해지는 데 대한 trade-off가 분명히 있다. 대표적으로 기능의 한계다. list comprehension을 생각해보자. list comprehension을 사용하면 list를 손쉽게 생성할 수 있지만 짧은 문법을 통해 매우 복잡한 요구사항의 리스트를 한 줄로 만드는 것은 어렵거나 불가능하다. 가령 2차원 행렬의 곱을 구할 때 이를 list comprehension을 통해 한 줄로 구현할 수도 있겠지만(여기서는 generator expression), 가독성이 지독하게 나빠지기 때문에 이 방법은 쓰지 않는 게 좋다. 그냥 일반적인 for문 활용을 통해 해결하는 게 최선이다.(여기서는 ‘yield’를 활용한 generator)
또 Generator를 만드는 대신 (일반적으로 코드가 더 긴) Iterable, Iterator를 만드는 게 더 열등하냐고 하면 그것도 아니다. 이 방법의 결정적인 장점은 Iterable과 Iterator가 서로 다른 역할을 하도록 역할분담이 가능하다는 것이다. 다른 말로 하면 Modularity가 실현됐다. Iterable은 Iterable 나름의 역할이 있고, Iterator는 또 나름의 역할과 책임이 있다. Generator는 이 둘의 기능을 합쳤기 때문에 쉬운 활용에서는 더 편하지만, 매우 복잡한 프로그램에서 둘의 기능을 분리하고 싶을 때 좋은 선택이 될 수 없다.
즉 보다 복잡한 프로그램일수록 Iterator protocol을 준수한 Iterable, Iterator를 만들어 쓰는 것이 좋은 선택일 수 있고, 프로그램이 매우 단순하다면 Generator expression을 사용하는 방법이 더 바람직할 수 있다. 명심하자. 진리에 버금가는 해결책은 없다. 그렇다면 상식적으로 그 옵션이 경쟁자를 모두 멸종시켜 역사책에서나 등장하게 만들었을 것이다.
마지막으로 Generator expression의 매우 중요한 활용처를 살펴보자. 이 내용은 이 포스트의 다른 내용은 까먹어도 기억해야 한다.
예를 들어서, 내가 1부터 10까지의 값의 제곱을 모두 더한 값을 구한다고 하자. 뭔가 내장함수 sum을 쓰면 될 것 같은데 list comprehension을 알고 있다면 이렇게 쓸 수 있겠다.
print(sum([n ** 2 for n in range(1, 11)]))
385
이 정도만 되어도 답은 나오는데 이런 풀이는 하수다. 이를 Generator expression을 써서 구할 수도 있다. 사실, 이런 문제에서는 generator를 쓰는 것이 성능이 더 좋다.
print(sum((n ** 2 for n in range(1, 11))))
385
[] 대신 ()를 사용해도 값은 똑같이 나온다. 좋다. 이때 만약 generator expression이 함수의 유일한(sole) 인자라면, expression의 ()를 생략해도 된다.
sum(n ** 2 for n in range(1, 11))
385
괄호의 개수를 정확히 파악하기 위해 print 함수를 지웠다. 말 그대로, generator expression이 어떤 함수의 단일 인자라면 ()를 쓰지 않아도 된다. 어차피 함수 호출을 위해 ()가 쓰이니 가독성을 위해 허락하는 것 같다. 다음과 같은 예도 만들어봤다.
print(n ** 2 for n in range(10))
<generator object <genexpr> at 0x7f0801e6b0f8>
하지만 함수의 인자가 두 개 이상일 때 ()를 생략하면 SyntaxError가 발생한다. 꼭 기억하자.
4.4. 상속 관계
앞서 Iterator와 Iterable에 대해 살펴보면서 이 둘의 상속관계도 확인했다. 결과 Iterator는 Iterable의 서브 클래스라는 것을 알 수 있었다. 그러면 Generator도 이 상속관계에 낄 수 있을까? 음 못할 것도 없을 것 같은데 아까와 같은 방식으로 살펴보자.
Generator는 Iterator와 비교하면 된다. 앞서 상속관계를 확인할 때 사용했던 명제를 여기에도 적용할 수 있겠다:
- Generator는 Iterator다.
- Iterator는 Generator다.
각 명제의 참/거짓 여부를 확인해보자.
- Generator는 Iterator인가?
어떤 객체가 Iterator이기 위한 조건은 __iter__를 통해 자신을 반환해야 하고, __next__를 통해 다음 값을 반환하고 커서를 다음으로 옮겨야 한다.
Generator는 이 조건을 만족하는지?
g = (i for i in range(10))
# 1.
assert g == iter(g)
# 2.
print(next(g))
print(next(g))
print(next(g))
0
1
2
Generator expression을 통해 Generator를 만들었다. # 1.을 통해 iter 함수를 사용해 자신이 반환되는지 확인해보니 AssertionError가 반환되지 않았다. 즉, 첫 번째 조건을 만족한다. # 2.를 통해 두 번째 조건을 확인해도 마찬가지다. next 함수를 쓸 때마다 Generator의 다음 값이 반환되고 있다. 만약 10개의 값을 모두 반환하면 StopIteration이 걸릴 것이다. 즉 두 번째 조건도 만족한다. 이를 통해 ‘Generator는 Iterator다’라는 명제는 참이라는 것을 알 수 있다.
- Iterator는 Generator인가?
미안. 이건 개념적으로 정확히 이해 못했다. 어떤 객체가 Generator이기 위한 정확한 조건을 파악하지 못했다. yield 식을 쓰거나, ()를 통해 생성해야 하나? 아니면 dir(Generator) 를 통해 확인할 수 있는 Generator만의 메소드인 send, throw, close를 Iterator가 가지고 있어야 하나? 이건 넘어가도록 하자.
대신 issubclass 함수를 통해 실제 코드로 상속관계를 파악하자.
print(issubclass(Generator, Iterator))
print(issubclass(Iterator, Generator))
True
False
결론은 확실하다. Generator는 Iterator의 자식 클래스다. 하지만 그 역은 성립하지 않는다. 세 ADT의 상속관계가 일렬로 정렬됨을 확인할 수 있다.
Iterator는 Iterable의 자식 클래스다. Generator는 Iterator의 자식 클래스다. 따라서, Generator는 Iterable의 자식 클래스다.
5. 이들의 존재의 의미를 묻는다
어쩌면 이번 포스트의 핵심이 되는 부분이다. 우리는 이 긴 내용을 통해 Iterable, Iterator, Generator를 살폈는데 이것들을 왜 배운걸까? 사실 결과만이 목적이면 이런 어려운 것을 공부할 필요없이 일반 list comprehension를 쓰거나, 함수를 만들어쓰면 같은 결과를 구할 수 있다. 우리의 랜덤 정수 예제도 그냥 list로 반환해서 써도 어지간한 요구사항은 똑같이 만족시킬 것이다. 그럼에도 불구하고 어떤 추가적인 장점이 있기에 Generator나 Iterator를 쓰면 좋은 것일까? 그 장점은 다음과 같이 말할 수 있다:
Lazy evaluation을 통한 메모리 안전성
이 구절의 정확한 의미를 이해하기 위해 for문에서 같은 결과를 내는 list comprehension과 generator를 비교해서 살펴볼 것이다. for문을 통해 1부터 10까지 출력하고 싶다고 하자. 이때 ‘in’ 키워드 뒤에 다음과 같은 list와 generator를 각각 둬서 같은 결과를 낼 수 있다.
# 1. list를 활용해 결과 출력
for e in [n for n in range(1, 11)]:
print(e)
1
2
3
...
# 2. Generator를 사용해 결과 출력
for e in (n for n in range(1, 11)):
print(e)
1
2
3
...
위 두 식은 정확히 같은 결과를 출력하면서 식도 비슷하다. 차이라면 식을 완성하기 위해 [], ()를 썼는지 정도다. 첫 번째에서는 list가 반환돼서 쓰였고, 두 번째에서는 Generator가 반환돼 쓰였다. 하지만 이 둘에는 큰 차이가 있는데 내부적으로 컴퓨터 메모리와 관련이 있다.
먼저 리스트를 만들었던 첫 번째 예를 살펴보자. 리스트를 선언하면 하드웨어적으로 메모리에 그 리스트를 위한 공간이 할당된다. 그것을 그림으로 표현하면 다음과 같다.
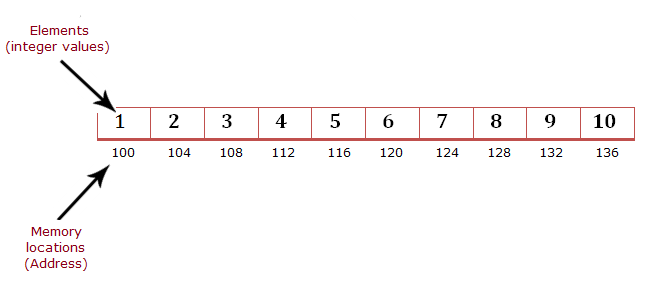
C 같은 언어(C-like language)에서는 일반적으로 정수 배열이 메모리 상에 연속적으로, 단절 없이 할당된다. 그리고 여기서 쓰인 정수는 int 형으로 4 바이트를 차지한다. 위 그림에서 각 셀이 배열(array)의 한 원소를 나타내고 셀의 바로 밑에 있는 숫자는 각 원소가 차지하는 메모리의 위치 주소를 의미한다. 주소 숫자 간격이 4라는 것을 알 수 있다. 파이썬에서 list가 C에서의 array와는 구현이 조금 다르지만 중요한 것은 1번과 같이 list comprehension 식을 입력했을 때 메모리에 배열의 크기에 비례하는 공간이 바로 할당된다는 것이다. 위의 예에서라면 10개의 정수가 배열에 있으므로 이 배열의 총 크기는 40 byte(\(4 X 10\))가 될 것이다.
하지만 두 번째는 다르다. generator expression을 통해 생성한 generator는 숫자 10개를 생성할 예정이지만 그것을 배열 등의 구체적인 형태로 가지고 있지 않다. 다른 말로 하면 generator expression은 지정한 규칙대로 값을 반환할 규칙과 현재 어디까지 반환했는지 등을 관리할 여러 상태값을 담고 있지만 배열과 달리 값 모두를 generator를 생성할 당시에 메모리에 할당하지 않는다는 결정적인 차이가 있다. 이게 첫 번째 예제로 만든 list와의 큰 차이로서 이런 형태의 디자인 패턴을 lazy loading이라고 한다. 이 lazy loading이라는 패턴은 생각보다 흔히 쓰이기 때문에 기억하고 있으면 좋다. 반대로 첫 번째 예제처럼 생성과 동시에 메모리에 적재하는 패턴은 eager loading이라고도 한다. 포스트의 로고 사진이 게으른(lazy) 나무늘보인 것은 사실 이런 깊은 뜻이 있었다.
다음과 같은 질문을 던질 수 있다. 왜 굳이 이 둘을 분리해서 쓰는가? 결국 generator(iterator)를 통해 할 수 있는 모든 일은 list comprehension(기본 list)으로 잘할 수 있는데 말이다. 쓸데없이 문법을 만들어서 이 길고 긴 포스트를 읽게 만드는 고생을 하게 만들고 있다고.
잠깐만. 존재 이유를 단 한 번에 보여주겠다. 앞선 예제에서 만든, eager loading을 채택하는 list는 크기가 10이었는데 이런 작은 값이 아닌 크기가 매우 큰 경우는 어떨까?
big_list = [i for i in range(1, 100000000000000000000+1)]
# 생성이 안 됨
아까와 달리 크기가 매우 큰 list를 생성하는 list comprehension이다. range 함수 내의 두 번째 인자가 정확히 몇인지 눈으로 셀 수도 없을 정도다. 저 한 줄을 복사해서 파이썬 인터프리터에 실행시켜보라. 결과가 어떻게 나올까?
아마 멈추거나 인터프리터가 종료되거나 할 것이다. 그 이유는 list 같은 자료구조는 eager loading으로 원소의 크기에 따라 총 크기가 결정되므로 저렇게 큰 크기의 list를 선언하면, 일반 컴퓨터의 한정된 용량의 메모리로는 감당할 수 없기 때문이다. 메모리의 크기가 가상 메모리를 사용한다고 해도 일반 컴퓨터는 어지간하면 100 기가바이트를 넘지 않을텐데 그것을 상회하도록 크기를 크게 만든 자료구조는 생성할 수 없다.
반대로 저것과 같은 크기의 값을 생성할 generator는 문제없이 실행된다.
big_gen = (i for i in range(1, 10000000000000000000000000000+1))
# 문제없이 바로 생성됨
심지어 지금 만든 generator는 앞선 big_list 보다 생성할 값의 크기가 훨씬 더 크다.
이렇게 매우 큰 크기를 갖는 자료구조를 다룰 일이 현업에서는 생각보다 더 흔하다. 매우 큰 파일을 읽는다거나, 네트워크를 통해 대용량의 데이터를 다운로드할 때를 생각해보면, 줄 등의 한 단위를 필요할 때 한 줄씩 평가하는(evaluate) lazy loading이 한 번에 모든 데이터를 loading하는 방식보다 안전한 것은 명약관화하다.
정리하면, iterable, iterator, generator의 장점은 일련의 값을 사용할 때 모든 값을 메모리에 모두 로딩하는 대신 한 값씩 필요할 때마다 로딩, 평가함으로써(lazy loading, evaluate) 메모리를 절약하고, 관련해 메모리 부족으로 프로그램이 실패하는 것을 방지할 수 있다는 것이다. 즉, 안전성이 담보된다.
6. 마치며
아, 솔직히 너무 짜증난다. 내 vim 기준으로 이 포스트가 처음으로 1000줄을 넘겼다. 내용이 길다는 것 자체는 문제가 아닌데, 여기까지 이르는 과정이 순탄치 않았다. 포스트를 쓰기 직전에 쓰는 포스트 구성이 매우 구체적이지 않아서 쓰면서 내용이 예상보다 계속 길어졌고, 결과적으로 내용이 단순하고 깔끔하지 않아진 것 같다. 지금 생각하면 관련 내용을 두세 포스트 정도로 쪼갰어야 하는 생각이 든다. 특히 collections.abc는 개인적으로 관심이 많고 또 재미있는 주제라서 언제 다루면 좋은데 이번 포스트를 위해 불가피하게 길게 서술해야 했다. 차라리 이 포스트를 쓰기 전에 이것과 관련해서 심도 있게 써야 했을까? 포스트를 몇 개나 썼는데 아직도 이런 불완전성을 보이다니. 나는 프로가 아니다. 반성한다.
실패만 한 것은 아니다. 이 주제로 포스트를 써야겠다고는 꽤 오래 전부터 생각은 하고 있었다. 일단 쓰긴 썼으니까 그 짐은 덜기는 했는데 앞에 서술한 이유로 찝찝한 것을 감출 수는 없다. 아쉽다.
독자분들께. 이 포스트는 정보량 자체는 적지 않고, 내용도 부실하지 않다고 자체 평가하고는 있는데 긴 내용을 몰아쓰다보니 내용 간의 흐름이 매끄럽지 않다거나, 부정확한 내용, 오탈자나 비문 등이 평균보다 높을 수 있다고 생각합니다. 따라서 애매한 부분이 있으면 주저없이 관련 내용을 댓글로 달아주시면 매우 감사하겠습니다. 바로 확인 후 조치할 수 있도록 하겠습니다.
어디 가서 글 쓴다고 티내지 않아야겠습니다. 저는 실력이 있다면 무조건 겸손할 필요는 없다고 생각하는데, 반대로 자신을 과대평가하지는 않아야겠다고 다시금 느꼈습니다.
이상 포스트를 마칩니다.
7. 자료 출처
- stack overflow: What exactly is Python’s iterator protocol?
- python.org: iterator types
- python.org: StopIteration
- python.org: generator expression
- python.org: datamodel