
Python의 핵심 내장 자료구조 살펴보기
0. Index
- 이 포스트는 데잇걸즈 3기 분들을 위해 제작되었습니다.
1. 들어가며
뭐든지 처음이 어렵다. 특히 인간의 직관에 반하는 무언가를 배울 때는 더 그런 것 같다. Python(이하 “파이썬”)은 하드웨어에 대한 지식이 (많이) 없어도 되는 고급언어지만 그래도 처음 공부하는 분들에게는 꽤나 어려울 수 있겠다고 최근에 더 느꼈다. 요즈음 보면 컴퓨터 공학 자체보다는 데이터 분석이나 머신러닝 등의 작업을 하는 분들이 파이썬을 많이들 공부하는 것 같다. 이때 중요한 건 본인들의 창의적인 작업에 시간을 더 많이 쏟으려면, 구체적인 문법과 같은 덜 창의적인 작업은 빨리 이해하고 넘어가는 것이 좋다는 것이다.
오늘 포스트는 그런 분들을 위한 포스트다. 본인들의 창의적인 작업을 위해 프로그래밍을 공부하는, 하지만 당장 파이썬 언어에 전문가까지는 바라지 않는 분들. 그러려면 어떤 내용을 다뤄야할까 고민을 하다가 떠오른 것이 내장 자료구조다. 모든 언어에는 해당 언어에 핵심적인 자료구조가 있기 마련이다. 그 언어를 사용하려면 이 자료구조들의 기본적인 특징 정도는 확인하고, 필요할 때 사용할 수 있는 수준은 되어야 할 것이다. 파이썬에는 핵심 내장 자료구조가 list, tuple, set, dict 등 네 가지가 있으며 이들을 세심히 살펴볼 생각이다.
글을 쓸 때는 예상 독자층을 정하고 시작하는 것이 기본이다. 완전 초심자들을 목표로 써보는 것이 정말 오랜만인데 어디 한 번 내 집필 능력을 다시금 테스트해보자. 쓴다고 써왔는데 과연 나는 성장했는지.
2. 개요
이 포스트의 목적은 파이썬의 핵심 내장 자료구조(list, tuple, set, dict)에 대해 잘 이해하고, 문제상황에서 가장 적절한 자료구조를 선택하고 활용하는 능력을 함양하는 데 있다.
주 대상 독자층은 프로그래밍을 파이썬으로 처음 공부하는 초심자로, 파이썬 전문가를 목표로 하기보다는 자동화, 머신러닝, 데이터 분석 도구로써 파이썬을 만지는 분들을 대상으로 한다. 따라서 모토는 더 쉽게, 더 간단하게, 더 풀어서가 된다. 각 자료구조를 최대한 상세하게 설명하려고 노력할 것이며 초심자들을 괴롭게 하는 어려운 용어는 사용하지 않는다. 특히 개인적으로 아쉬운 부분은 각 자료구조와 관련해 메모리, 시공간 효율 등을 언급하지 않는다는 것인데 냉정히 생각하면 이 포스트의 예상 독자분들에게는 list의 시간 효율이 어쩌고와 같은 내용은 정말 필요없다고 다시금 느낀다.
몇 줄 위에서 어려운 용어는 사용하지 않는다고 했다. 하지만 이후 내용을 위해서 같이 알아야 할 필수적인 용어들이 있다. 이 부분은 어떤 이유로든 프로그래밍을 하는 이상 알면 좋겠다고 생각하기 때문에 이 gist에 정리했다. 협업하는 동료들과 사용하는 용어에 대한 공통된 이해가 없다면 개념을 소통하기가 매우 힘들어진다. 그래서 불가피하게 설명하게 됐으니 이해해주셨으면 좋겠다. 그리고 이 내용은 알면 결코 해가 되지 않는다. 따라서 본 내용으로 들어가기 전에 해당 문서를 먼저 확인해주시면 감사하겠다. 뒷 부분의 내용은 저 문서에 정리된 내용은 이해하고 있다고 가정하고 풀어나가겠다.
다음에는 list, tuple, set, dict에 각각 한 장씩 할애해서 이들에 대해 세심히 살핀다. 이해를 돕기 위한 비유부터 생성 방법, 특징, 핵심 메소드, 활용 예제에 한 절씩 할애한다. 특히 활용 예제를 살펴봐주길 바란다. 어떤 문제상황에 더 적절한 자료구조가 있을 수 있고, 이 상황을 잘 판단하는 것이 좋은 프로그래머다. 사실 이 포스트의 핵심 목적은 이 능력을 함양하는 데 있다.
마지막으로 네 자료구조의 특징을 한 번 더 정리하고 표로 정리한 뒤 포스트를 마친다.
3. list: 일렬로 줄 세운 자료형태 1
list는 파이썬의 가장 기본적인 자료구조다. 분명 어지간한 파이썬 기본 서적이나 강의들은 자료구조에서 list를 제일 먼저 설명할 것이다. 물론 나도 마찬가지다.
언급하고 싶은 것은 list와 tuple은 매우 중요한 특성을 공유한다. 그리고 경험상 tuple보다는 list를 압도적으로 더 많이 쓴다. 따라서 list 부분을 보다 상세하게 설명하고, tuple은 가볍게 설명하겠다. list에서 설명하는 많은 특징이 tuple에서 적용될 것이라 생각하면 무리없다. list와 tuple은 많은 특징을 공유하기 때문에 공통점보다는 차이점이 더 중요하다. 따라서 둘의 차이점은 tuple 부분에서 강조할 것이니 잘 숙지하고 가자.
3.1. 개요
동서고금을 막론하고 대다수의 사람들이 불만 없어하는 자원분배제도가 있다면 바로 대기열제다. 영어로는 Queue라고 하며 이 제도 하에서 사람들은 자신을 포함해서 사람들이 자리를 차지한 순서대로 자원이 분배되리라 너무나 당연하게 생각하며 보통 그렇게 된다. 이것이 정말 합리적인가 라는 질문은 뒤로 차치하고, 대기열제의 중요한 특징이 있다. 대기열제에서 중요한 것은 사람들이나 자원은 일렬로 세워져 고유한 순서를 가질 수 있으며, 때로 번호표 등의 이름으로 순서에 숫자를 매길 수 있다는 점이다.

list는 사람이나 자원을 줄 세우고, 이들에게 숫자로 된 번호를 매긴 자료구조다. 가령 대기열제에서 먼저 온 사람 순서대로 1번부터 N번까지 번호를 매겨 대기열을 관리할 수 있을 것이다. 그러면 ‘3번째로 서 있는 사람은 누구인가?‘와 같은 질문을 할 수 있다.
3.2. 생성
모든 자료구조는 자신을 생성하는 문법(syntax)을 가지고 있다. 이 문법만큼은 외워야 한다. list를 생성하는 방법은 크게 세 가지다.
한 방법은 []라는 기호를 사용해서 list를 생성하며, 그 안에 채워넣을 값들을 입력한다. 이때 값들은 ,로 구분한다.
l = [1, 2, 3, 4, 5]
print(type(l))
print(l)
<class 'list'>
[1, 2, 3, 4, 5]
l이라는 변수에 크기 5인 list를 할당했다. 값은 1부터 5까지의 자연수로, 이들은 실제로 일렬로 서있는 형태가 된다. 다음 절에서 이를 확인할 것이다.
위 방법이 list를 생성하는 대표적인 방법인데 list라는 생성 함수를 직접 사용해서 생성하는 방법도 있다. 사용법은 다음과 같다.
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range 함수는 아마 for 문을 공부할 때 보셨을텐데, 저 range 식을 간단하게 설명하자면 0부터 10미만까지의 정수가 반복할 예정이 되어 있는 기능이라고 하면 될 것 같다. range는 인자를 최대 세 개까지 받을 수 있는데 인자의 개수를 1, 2, 3개로 함에 따라 동작방식이 조금씩 다르다. 가령 range(10, 100) 처럼 적으면 ‘10부터 100 미만까지 반복할 예정이다’라고 생각하면 무난하다. 일단은 여기서 넘어가자.
이 range 함수의 결과물을 list라는 함수의 인자로 넣으면 0을 포함하는, 10 미만의 정수를 원소로 하는 list가 반환된다.
list 함수는 받은 인자가 range, tuple 등 반복할 수 있는 대상일 경우 이를 모두 사용해 list로 만든다.
다른 예도 만들어보자.
list(reversed(range(10)))
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
reversed 는 어떤 반복이 가능한 대상을 뒤집는 역할을 하는 내장 함수다. 인자로 받은 range 의 숫자들을 뒤집어놓으며 이를 list 로 실행하면 뒤집힌 원소들이 실제 list로 반환된다.
마지막 생성방법은 +, * 연산자를 사용하는 것이다.
먼저 + 연산자의 피연산자를 모두 list로 하면 이 둘이 접합해(concatenate) 새로운 list가 반환된다.
[1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
이때 새로 반환된 list는 앞선 두 list와는 완전 별개의 list가 된다. 즉, 이 list를 어떤 식으로든 지지고 볶아도 피연산자 list들에는 영향을 미치지 않는다.
다음은 *를 사용하는 것으로 이 방법은 왼쪽에 list, 오른쪽에 횟수(int) 피연산자를 받아 list를 횟수번만큼은 반복해 새 list를 생성한다.
l = [0] * 5
m = [1, 2, 3] * 3
print(l)
print(m)
[0, 0, 0, 0, 0]
[1, 2, 3, 1, 2, 3, 1, 2, 3]
이 방법은 때때로 꽤 유용하다. 가령 모든 원소가 ‘0’이고 크기가 N인 list를 생성해야 하는데 이걸 []로 일일히 다 입력하는 것은 매우 가슴아플 것이다. 이럴 때 *를 사용하는 방법이 꽤 편리하다.
3.3. 특징
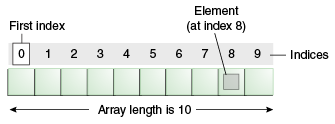
list는 앞서 본 대기열과 유사하다. 대기열에서는 원소를 일렬로 줄 세우며, 그들에게 도착번호와 같은 숫자를 매길 수 있다고 했다. 그를 통해 ‘3번째로 서 있는 사람이 누구냣!’과 같은 질문을 할 수 있다. 이렇게 list, tuple에서 N번째의 원소를 호출 또는 구하는 것을 indexing이라고 하며 indexing을 할 수 있다는 것이 list의 대표적인 특징이 된다.
특정 원소를 호출하는 방법은 list 바로 뒤에 []를 붙여서 그 사이에 호출하고자 하는 순서(숫자)를 입력하면 된다.
l = [1, 2, 3, 4, 5]
print(l[0])
print(l[1])
print(l[2])
print(l[3])
print(l[4])
1
2
3
4
5
indexing을 통해 1부터 5까지 출력했다. 이때 중요한 것은 우리가 접할 수 있는 대부분의 프로그래밍 언어의 배열에서 처음 시작 번호는 1이 아닌 0이 된다. 따라서 첫 번째 원소를 구하려면 0, 4번째 원소를 구하려면 3, N번째 원소를 구하려면 N-1로 indexing을 해야 한다. 이는 정말 중요하고, 처음 공부할 때 흔히 하는 실수이니 꼭 숙지하도록 하자.
list의 크기를 넘기는 번호로 indexing를 하면 에러가 발생한다.
l[1000000000000]
IndexError: list index out of range
이는 상식적으로 10명이 서 있는 대기열에서 12321번째 사람을 찾을 수는 없기 때문이다.
참고로 파이썬에서는 indexing할 때 숫자로 음의 정수를 입력할 수 있다.(negative indexing) 그러면 맨 뒤에서부터 세기 시작한다.
l = ['a', 'b', 'c', 'd', 'e']
print(l[-1])
print(l[-2])
print(l[-3])
e
d
c
indexing에서 -1은 ‘끝에서 맨 뒤’라는 의미를 갖는다. 이는 일반 indexing과는 다른데 l[1] 이 ‘앞에서 첫 번째’를 의미하지 않기 때문이다.(두 번째를 의미한다) 참고하도록 하자.
3.4. 핵심 메소드
list는 자료구조로 꽤 많은 메소드를 갖고 있다. 앞에서 잠깐 살펴봤는데 어떤 값이나 자료구조가 갖고 있는 메소드 등을 확인하는 내장 함수로 dir 가 있다. 이 함수를 통해 list가 내부적으로 무엇을 가지고 있는지 확인해보자.
print(dir(list))
['__add__', '__class__', '__contains__', '__delattr__', ...생략..., '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
상당히 많은 값이 나왔는데 앞 뒤로 __가 있는 값은 일단은 무시해도 된다. 그외에 append부터 sort까지가 list에서 사용자가 써볼법한 메소드로 현재 내 파이썬 버전에서는 10개가 좀 넘는다.
이 메소드를 다 외워야 할까? 당연히 그렇지 않다. 현실적으로도 힘들고 효율이 좋지도 않을 것이다. 가령 난 insert 메소드를 알고는 있지만 거의 써본 적은 없는 것 같다. 행여나 필요한 순간이 온다면 그때 검색해서 사용하면 된다.
그렇지만 유용하고 자주 쓰는 메소드들은 알고 있어도 나쁘지 않다. 경험상 많이 써본 list의 메소드를 몇 가지만 살펴보자.
3.4.1. list.append
개인적으로 list에서 가장 많이 쓴 메소드인 것 같다. ‘append’는 영어로 ‘덧붙이다’, ‘첨부하다’라는 뜻으로 그 뜻에 걸맞게 인자로 받은 값을 해당 리스트의 맨 뒤에 붙인다. 예제를 바로 살펴보자.
l = [1]
l.append(2)
l.append(3)
print(l)
[1, 2, 3]
뒤에 붙이는 연산은 꽤 자주 하기 때문에 이 함수는 알고 있으면 좋다. 여기서 추론할 수 있는 list의 특징은 이 자료구조의 크기를 늘리고, 값을 바꾸는 등 변형을 가할 수 있다는 점이다. 이는 tuple과의 큰 차이점이기 때문에 한 번 짚고 간다.
3.4.2. list.pop
list.pop 메소드는 append와 반대되는 일을 한다. list.pop은 해당 list의 맨 뒤의 값을 빼내서 반환하는 역할을 한다.
l = list(range(1, 6)) # [1, 2, 3, 4, 5]와 동일
print(l.pop())
print(l.pop())
5
4
append가 인자를 받아서 그 인자를 list의 끝에 붙였다면 pop은 인자를 받지 않고 맨 뒤의 값을 빼낸다. 또 중요한 차이가 있는데 append는 맨 뒤에 값을 붙이고 값을 따로 반환하지 않았다. 반면 list.pop은 값을 반환해서 이를 변수에 할당해 사용할 수 있다.
l = [1, 2, 3, 4, 5]
v = l.pop()
# v = l.append(5) 같은 식은 ㄴㄴ
# list.append는 값을 반환하지 않기 때문
print(v)
5
이 메소드도 꽤 자주 쓰니 기억 정도는 하고 있자!
3.4.2. list.sort
list.sort 또한 중요하다. sort는 ‘정렬하다’라는 뜻을 가지고 있고 말 그대로 list 안의 원소들을 오름차순 정렬한다.
l = [5, 3, 2, 1, 4]
print(l)
l.sort()
print(l)
[5, 3, 2, 1, 4]
[1, 2, 3, 4, 5]
이전 list에는 1부터 5까지의 정수가 마구 섞여 있었다. 이런 상황에서 list.sort 메소드를 실행하면 안의 원소들이 모두 오름차순 정렬된다. 이때 기억할 것은 이 변화는 영구적인 변화로서 다시 원래의 상태로 돌아갈 수 없다. 주의하자.
또한 기본 동작은 오름차순이지만 원하면 내림차순으로 바꿀 수 있다. 이때는 메소드의 reverse 라는 인자에 True 값을 주면 된다.
l = [5, 3, 2, 1, 4]
print(l)
l.sort(reverse=True) # !!!
print(l)
[5, 3, 2, 1, 4]
[5, 4, 3, 2, 1]
list.sort는 데이터를 다루는 입장에서 자주 쓰게 될 수도 있겠다. 참고하자 :)
3.5. 사용 예제
각 자료구조마다 해당 자료구조를 사용하면 바람직한 예를 한 두개씩 만들어볼까 한다.
정수를 가득 담은 list가 있다고 하자. 이때 짝수만 담은 새로운 list를 만들어야 하는 문제상황이 주어졌다. 이 문제를 해결하는 무난한 방법은 for문과 list를 사용하는 것이다.
l = [1, 2, 5, 3, 4, 5, 7, 4, 5, 2, 3, 3, 1,
3, 4, 3, 4, 6, 6, 5, 1, 4, 9, 7, 3, 8]
대상이 되는 list는 위와 같다고 하자. list의 크기를 더 크게 하고 싶은데 이 정도로 일단 만족하자. 아직 공부하지 않은 다른 문법을 사용하면 크기를 백만이든, 수천만이든 설정할 수 있다.
for 문을 사용해서 짝수만 담는 코드는 다음과 같이 만들 수 있겠다.
evens = []
for n in l:
if n % 2 == 0:
evens.append(n)
print(evens)
[2, 4, 4, 2, 4, 4, 6, 6, 4, 8]
for 문을 통해 l 의 원소를 하나씩 순회하면서 해당 원소가 짝수라면, 다시 말해 2로 나눈 나머지가 0이라면 evens 라는 list에 담는다.(append) 결과 짝수들만 모인 것을 확인할 수 있다.
4. tuple: 일렬로 줄 세운 자료형태 2
4.1. 개요
앞선 list의 대표적인 특징은 list 자료구조가 데이터들을 일렬로 줄세워 이들을 indexing할 수 있는 것이라고 확인했다. tuple도 그 계보를 잇는다. 이 특징을 공유하기 때문에 list와 tuple은 매우 비슷하게 쓸 수 있는데 결정적인 차이 또한 존재하는 것도 사실이다. 3장의 list의 내용은 상당 부분 tuple에도 적용가능하다고 말했었다. 정말 그런지 확인할 것이며, list와의 차이점 또한 확실하게 짚고 넘어가도록 하자.
4.2. 생성
tuple을 생성하는 데는 list의 세 가지 방법을 그대로 사용할 수 있다.
먼저 기호를 사용하는 방법으로 list에서 []를 사용했다면 tuple에서는 ()를 사용한다.
l = (1, 2, 3)
print(type(l))
print(l)
<class 'tuple'>
(1, 2, 3)
두 번째 방법은 마찬가지로 tuple 생성 함수를 사용하는 것이다.
print(tuple(range(5)))
print(tuple(reversed(range(5))))
(0, 1, 2, 3, 4)
(4, 3, 2, 1, 0)
list 때와 기호만 다르고 만드는 방법은 똑같다.
세 번째 방법인 *, +를 사용하는 것도 list 때와 정확히 똑같다.
print((1, 2, 3) * 3)
print(('a', 'b') + ('c', 'd', 'e'))
(1, 2, 3, 1, 2, 3, 1, 2, 3)
('a', 'b', 'c', 'd', 'e')
이를 통해 ‘모르긴 몰라도 list와 tuple이 정말 많은 공통점을 공유하겠구나’라고 생각할 수 있다. 실제로도 그렇다.
4.3. 특징
tuple은 list와 많은 특징을 공유한다고 누차 말했다. 이제 결정적인 차이를 살펴보자. tuple은 list와 달리 한 번 생성된 값을 변형할 수 없다.
먼저 list에서 값을 변형할 수 있다는 것을 살펴보자.
l = [1, 2, 3]
print(l)
l[1] = 1000000
print(l)
[1, 2, 3]
[1, 1000000, 3]
처음에는 [1, 2, 3] 이라는 연속된 값을 갖는 list를 선언했다. 그러고는 2의 값을 갖고 있던 1의 인덱스에 1000000라는 무시무시한 값을 넣었다. 이때 에러가 발생하지 않았고 따라서 list는 변형이 가능하다는 것을 알 수 있다. 우리가 살펴본 list.append 등도 다 원래의 값과 형태를 변형시키는 역할을 하고 있는 것이다.
반면 tuple은 한 번 생성하면 값을 바꿀 수 없다.
l = (1, 2, 3)
print(l)
l[1] = 1000000
print(l)
[1, 2, 3]
TypeError: 'tuple' object does not support item assignment
아까의 list 식에서 []만 ()로 바꿔 tuple로 다시 실행했는데 바로 에러가 난다. 에러 메시지에서 바로 말하고 있다. ‘튜플’ 객체는 아이템 할당을 지원하지 않는다. 이게 tuple과 list의 결정적인 차이다.
아마 일반적인 활용에서는 tuple보다는 list를 훨씬 많이 쓰게 될 것이다. tuple이 할 수 있는 모든 일은 list로도 할 수 있기 때문이다. 따라서 이런 결정적인 차이가 있다는 것만 기억하자.
4.4. 핵심 메소드
tuple은 list와 많은 특징을 공유함에도 append, sort, pop 등의 메소드를 쓸 수 없다.
print(dir(tuple))
['__add__', '__class__', '__contains__', ... 생략 ..., '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index']
이는 어떻게 보면 당연한데, append, sort 등의 메소드는 원 list를 변형시키는 메소드이기 때문에 할당 이후 변형시킬 수 없다는 tuple의 조건에 위배되기 때문이다. 그렇기에 tuple에서 사용가능한 메소드 목록에 이들의 이름이 없는 것은 자명하다. 대신 여기서는 count 메소드를 써보자.
count 메소드는 어떤 값을 받아서 tuple 내에 그 값이 몇 개 있는지, 다시 말해 빈도를 세는 메소드다. 사용방법은 간단하다.
t = (1, 2, 3, 4, 5, 1, 2, 1, 2)
print(t.count(1))
print(t.count(3))
3
1
1부터 5까지의 값을 담은 tuple에 count 메소드를 호출해서 1과 3이 몇 개씩 있는지 확인했다. 결과 1은 3개, 3은 1개가 있음을 알 수 있었다.
참고로 count 메소드는 list에서도 쓸 수 있다. tuple로 할 수 있는 일은 모두 list로도 할 수 있다는 말은 이런 뜻이다. 따라서 사용예제는 넘어가도록 하겠다.
* 커피 타임 가지세용... 저도 좀 쉬다왔음.
5. set: 자료의 중복을 허용하지 않는 집합
앞선 두 자료구조가 일렬로 정렬되어 순서를 매길 수 있는 자료구조였다면 다음 두 자료구조는 그렇지 않다. 먼저 set을 살펴본다. set은 자료의 중복을 허용하지 않는 자료구조로 list나 tuple 등에 산재해 있는 중복 원소를 제거하는 작업 등에 유용하다.
5.1. 개요
아직도 기억나는데 내가 고등학생 1학년이었을 때 집합(set)을 배웠다. 벤 다이어그램을 열심히 그려 차집합, 교집합, 합집합 등에 열심히 색칠하던 기억이 난다. 대충 이런 식이었다.
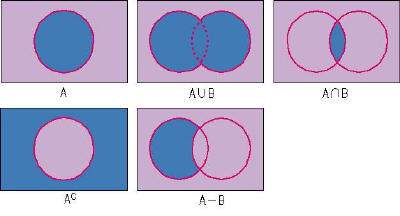
파이썬의 set은 수학의 집합을 자료구조로 표현한 것이다. 이게 핵심이다. 수학의 집합에서는 여러 원소를 담을 수 있고, 일반 사칙연산과는 다른 집합간 연산을 정의하는데 set 은 이 명세를 완벽하게 구현하고 있다. 곧 살펴볼 것이다.
5.2. 생성
list는 [], tuple은 ()을 통해 정의했다면 set은 {} 중괄호를 통해 정의한다. 기호 안에 똑같이 원소를 ,로 구분해 입력하면 된다.
a = {1, 2, 3, 'a'}
print(type(a))
<class 'set'>
{}를 통해 set을 생성했고 이를 a 변수에 할당했다.
또 다른 생성방법은 set 생성함수를 사용하는 것이다. 가령 1부터 10까지의 값을 갖는 set을 만드는 것은 이제 우리에게는 일도 아니다.
l = set(range(1, 11))
print(l)
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
생성 자체는 위의 두 자료구조와 크게 다르지 않은 것 같다. 다음 절에서 set의 매우 중요한 특징을 살펴보자.
5.3. 특징
먼저 set은 list와 tuple과 달리 원소간 순서가 없다. 앞선 list와 tuple은 일렬로 줄세운 자료구조로 번호로 indexing이 가능했지만, set은 모아놓는다는 정의에만 충실해서 순서 따위가 없다. 따라서 set에서는 indexing이 불가능하다.
s = {1, 2, 3}
print(s[0])
TypeError: 'set' object does not support indexing
‘집합’ 객체는 인덱싱을 지원하지 않는단다. 수학적 집합을 생각해봐도, 집합에 indexing을 요구하는 것은 마치 ‘데잇걸즈의 30번째 수강생은 누구인가?’와 같은 질문을 하는 것 같이 어불성설이다. 데잇걸즈에서는 딱히 어느 기준으로 줄 세우지 않았다. 단지 30여명의 자격을 얻은 수강생이 모여 있을 뿐.
두 번째로 set은 원소의 중복을 허용하지 않는다.(unique) 이게 정말 중요하다. 수학적으로 집합(set)이 중복된 원소를 가질 수 없는 것은 집합의 정의에서 기인하는 것으로 매우 당연하다.
이를 확인해보자. 먼저 list 등은 중복된 원소를 가질 수 있다.
print([0] * 5)
반면 set을 생성할 때 원소가 두 개 이상 중복되면 한 개만 남게 된다.
print({1, 1, 1, 1, 1, 1, 1, 1, 1})
{1}
set의 매우 중요한 특징이니 기억하도록 하자.
5.4. 핵심 메소드
set은 수학적인 집합을 구현한 자료구조라고 했다. 그렇다면 set은 집합의 연산에서 중요한 교집합, 합집합, 차집합 등을 구현할 것이라고 합리적인 추론을 할 수 있다. 실제로 그렇고, 이 메소드들을 살펴볼 것이다.
먼저 set이 어떤 기능을 갖고 있는지 dir 을 통해 살펴보자.
dir(set)
[ ... 생략 ...,
'__str__',
'__sub__',
'__subclasshook__',
'__xor__',
'add',
'clear',
'copy',
'difference',
'difference_update',
'discard',
'intersection',
'intersection_update',
'isdisjoint',
'issubset',
'issuperset',
'pop',
'remove',
'symmetric_difference',
'symmetric_difference_update',
'union',
'update']
뭐가 굉장히 많은데 내게도 생소한 것들이 많다. 즉, 다 몰라도 된다. 근데 이중에서 set.add 메소드는 써봤던 것 같다. 이 메소드는 단순히 값을 받아서 집합 안에 이 값을 추가한다.
s = {1, 2, 3}
s.add(4)
s.add(4)
print(s)
{1, 2, 3, 4}
s 라는 이름의 set을 정의하고 여기에 4를 추가했다. 결과 집합의 크기가 1 커졌다. 확인할 것은 4를 더하는 add 메소드를 두 번 호출했음에도 4는 한 번만 추가됐다는 점이다. 누차 강조하지만 set은 원소의 중복을 허락하지 않는다.
이제 본격적으로 set의 교집합, 합집합, 차집합 메소드를 살펴본다.
- 먼저 교집합. 교집합(intersection)은 두 집합에서 공통적으로 포함되는 부분을 추출하는 연산을 말한다. 어떤 집합에서 다른 집합과의 교집합을 구하는 메소드는 set.intersection이다.
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
print(a.intersection(b))
{4, 5}
두 집합 a, b에서 공통되는 부분은 {4, 5} 뿐이다. 메소드 호출 결과 정확히 출력되었음을 알 수 있다. 참고로 같은 작업을 & 연산자를 통해서도 실행할 수 있다.
print(a & b)
{4, 5}
- 다음으로는 합집합. 합집합(union)은 두 집합을 하나의 집합으로 온전히 합치는 것으로 연산 결과 공통되는 원소의 중복은 당연히 삭제된다. 한 집합의 다른 집합과의 합집합을 구하는 메소드는 set.union이다.
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
print(a.union(b))
{1, 2, 3, 4, 5, 6, 7, 8}
같은 작업을 | 연산자를 통해 할 수 있다. |는 키보드에서 백슬래쉬(\) 키를 shift 키를 누른 채로 입력하면 출력된다.
print(a | b)
{1, 2, 3, 4, 5, 6, 7, 8}
- 마지막으로 차집합(difference of sets)은 한 집합에서 다른 집합을 빼는 것으로 이때 두 집합의 교집합이 원 집합에서 삭제된다. 한 집합에서 다른 집합을 뺀 차집합을 구하는 메소드는 set.difference다.
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
print(a.difference(b))
{1, 2, 3}
a 에서 b 를 빼는데, 둘의 교집합은 {4, 5}다. 따라서 a 에서 {4, 5}가 빠지고 결과는 {1, 2, 3}이 남은 것을 확인할 수 있다.
같은 작업은 - 연산자를 통해서도 할 수 있다.
print(a - b)
{1, 2, 3}
5.5. 예제
set을 활용하기 딱 좋은 예제는 set의 원소의 중복을 허용하지 않는다는 특징을 이용해 데이터의 cardinality를 구하는 것이다. cardinality는 데이터에서 고유한 데이터가 얼마나 많은지를 판단하는 통계량이다. 가령 데이터베이스에서 고객의 정보를 저장하는데, 성별은 남/녀와 같이 두 개의 범주로만 구분할 수 있어 cardinality가 낮다고 할 수 있다. 반대로 평균 신장 같은 경우는(왜 저장하는지는 모르겠지만) 연속된 자료형으로 사람마다 다 다르기 때문에 cardinality가 매우 높다고 할 수 있다.
자료의 cardinality를 구할 때 set을 통해 unique한 자료들만 남기고 이들의 크기를 구하면 자료의 cardinality를 매우 쉽게 구할 수 있다.
data = ['남', '여', '남', '여', '여', '여', '남', '여', '여', '여']
print('data의 cardinality는', len(set(data)))
data의 cardinality는 2
이 작업은 list 등으로도 똑같이 할 수 있으나 set을 통해서 매우 간단하게 해결할 수 있음을 알 수 있다. 다른 방법이 궁금한 분들은 set이 아닌 다른 자료구조로 같은 작업을 해보는 것은 어떨지?
6. dict: 단어를 입력하면 그 뜻을 주는 사전
드디어 마지막이다. dict. dict는 매우 중요하다. 개인적인 생각으로는 dict에 list 다음의 중요도를 부여하겠다. 그렇기에 조금만 더 노력해서 완성하도록 하자.
dict는 앞선 세 자료구조와는 결이 조금 다르다. 앞선 세 자료구조가 단순히 값 자체를 저장하는 데 관심이 있었다면, dict는 키와 값 쌍을 저장하는 것이 핵심이다. dict 부분은 자세히 살펴보시길 바랍니다.
6.1. 개요
지금도 생각난다. 10여년 전 중학생 때 영어를 배울 때는 스마트폰이 없었고, 난 영단어 공부를 종이 영한사전을 통해 공부했다. 가령 ‘absurd’라는 단어가 궁금하면 사전에서 해당 단어의 위치를 찾아 단어의 뜻을 찾는 식이었다. 저 단어의 뜻은 ‘터무니없는’이란다.
dict 자료구조는 ‘dictionary’, 즉 ‘사전’의 줄임말이다. 사전에 단어와 그 단어의 뜻이 쌍으로 저장되어 있듯, dict 또한 찾고자 하는 값과 그 값이 의미하는 값을 쌍으로 묶어 저장한다. 이때 찾고자 하는 값을 key라고 하며, key의 위치에 저장되어 있는 의미, 값을 value라고 한다.
설명이 깔쌈하게 안 나오는데 일단 dict를 하나 만들어보고 좀 더 이야기하자.
6.2. 생성
dict 또한 기호를 사용해 만드는데 set처럼 {}를 사용한다. 각 쌍은 ,를 통해 구분하고 쌍 안에서 key와 value는 :를 통해 구분한다. 매우 간단한 dict 예시는 다음과 같다.
d = {'a': 1, 'b': 2, 'c': 3}
d 라는 dict 는 총 세 개의 쌍을 갖고 있다. 이때 ‘a’, ‘b’, ‘c’는 key들이고, 1, 2, 3은 value들이다. 이 자료구조는 어떻게 활용할까? 앞서 영한사전을 예로 들었는데 뒤집어 생각하면 ‘터무니없는’이라는 한글 뜻에 이르기 위해 ‘absurd’라는 단어를 찾았다고 할 수도 있다. 그렇다면 ‘absurd’는 key가 되고, ‘터무니없는’이 value가 된다. 즉, dict 에서 key는 특정 value에 이르기 위한, 찾기 위한 열쇠 또는 힌트가 된다.
밑의 절에서 key를 통해 value를 찾는 과정을 자세히 살펴볼 것이다.
dict 를 생성하는 방법은 위의 세 자료구조를 생성하는 방법이 다양했던 것처럼 dict 생성자 함수를 사용하는 방법 등 더 있다. 하지만 지금은 좀 까다로울 것 같고 지금 확인한 방법을 숙지하고 잘 쓰는 것을 일단 목표로 하자. 내 생각에는 dict 를 만들 때 저 첫 번째 방법을 압도적으로(약 95% 이상) 많이 썼던 것 같다.
6.3. 특징
dict 자료구조는 key와 그에 대응하는 value 쌍들을 원소로 하는 자료구조고, key를 통해 그에 대응하는 value에 접근할 수 있다. key로 value를 찾는 것은 indexing과 비슷한데 문법도 동일하게 []를 사용한다.
d = {'a': 1, 'b': 2, 'c': 3}
print(d['a'])
print(d['b'])
1
2
d 라는 dict 는 세 개의 key-value 쌍을 갖는데 그중 key는 ‘a’, ‘b’, ‘c’다. 이때 key를 통해 그에 대응하는 value에 이를 수 있다고 했다. 위의 코드는 바로 그 내용이다. d[‘a’] 를 통해 d 의 ‘a’ key에 대응하는 value를 호출할 수 있었다. 자료구조 내의 특정 값을 호출한다는 점과 문법에서 []를 사용한다는 점에서 list의 indexing과 비슷하지만, list의 indexing은 데이터 자체가 아닌 데이터의 순서를 입력하고, dict는 value에 맞게 미리 설정된 key를 입력한다는 점에서 확실히 다르다.
단순히 특정 key에 일치하는 value를 호출하는 것을 넘어, key와 value를 추가할 수도 있다.
d = {'a': 1, 'b': 2, 'c': 3}
d['d'] = 4
d['e'] = 1000000000
print(d)
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 1000000000}
= 대입 연산자를 통해 기존에 없던 key와 그에 해당하는 value를 추가했다. 결과 d 의 크기가 3에서 5로 증가되었음을 확인할 수 있다.
dict의 기억할만한 특징으로는 value는 중복이 가능하지만, key는 중복이 가능하지 않다는 것이다.
먼저 서로 다른 key가 같은 value를 가리키는 것은 전혀 문제가 되지 않는다.
my_dict = {'a': 1, 'b': 1, 'c': 1}
print(my_dict)
{'a': 1, 'b': 1, 'c': 1}
하지만 key가 중복되는 것은 허용되지 않는다. 이는 어쩌면 당연한데, key가 중복된다고 했을 때 해당 key의 value를 호출할 때 어느 값을 선택해야 할지 알 수 없기 때문이다.
strange_dict = {'a': 1, 'a': 2, 'a': 3} # 설사 문법적으로 된다고 해도...
print(strange_dict['a']) # 이 값을 구할 수가 없음 ㅠㅠ 1? 2? 3?
참고로 위와 같이 dict를 선언하면 맨 마지막에 ‘a’ key를 사용한 경우만 dict에 저장된다.
또한 기억해야 할 것은 set과 같이 dict에도 쌍간 순서가 없다. print 함수를 통해 값을 확인했어도 어디까지나 편의상 보여지는 순서일 뿐이다. dict의 크기가 변하거나, 추가적인 연산을 통해 값에 변화나 변형이 생기거나 할 경우 출력되는 순서가 얼마든지 변할 수 있다. 이는 set도 마찬가지다.
6.4. 핵심 메소드
dict에도 물론 많은 메소드가 있지만 이중 몇 가지만 살펴볼 것이다. dict를 for문에서 쓴다고 가정하고 이 상황에서 유용한 메소드를 먼저 살펴보자. 우리는 list를 for문에서 써서 list의 각 값을 순서대로 가져올 수 있음을 안다. dict 또한 for 반복문에서 쓸 수 있는데 이때 궁금한 것은, for 문에서 값을 받아오면 key를 받을까, value를 받을까??
d = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
for whatisthis in d:
print(whatisthis)
a
b
c
d
dict를 정의하고 바로 for문에서 실행해봤다. 이때 한 번에 한 번씩 나오는 값이 key인지 아니면 value인지 확인해본 결과 key를 받아온다. for 반복문에서 dict를 쓸 때의 기본동작이다.
하지만 여기서 끝이 아니다. 다음과 같은 상황이 발생할 수 있기 때문이다:
- for 문에서 dict를 쓸 때 key 대신 value를 받고 싶으면 어떡하지?
- 또는 key와 value를 모두 받을 수는 없을까?
물론, 둘 다 가능하다. 파이썬은 사랑이기 때문이다.
먼저 key 대신 value를 받아오고 싶다고 하자. 이때는 dict.values 메소드를 사용한다.
for v in d.values():
print(v)
1
2
3
4
다음으로 key와 value 모두를 받고 싶을 때는 dict.items 메소드를 사용한다.
for k, v in d.items():
print(k, '..!', v)
a ..! 1
b ..! 2
c ..! 3
d ..! 4
dict.items() 메소드는 한 번 for문에서 실행될 때마다 각 쌍의 key와 value를 모두 반환한다. 이때 첫 번째 변수 이름(여기서는 ‘k’)에 key가, 두 번째 변수 이름(여기서는 ‘v’)에 value가 할당된다. 결과 한 반복문에서 dict의 key와 value에 모두 접근가능함을 확인할 수 있었다.
다음으로 꽤 중요한 메소드로 dict.get 메소드가 있다. 이 메소드가 왜 필요한지를 먼저 이해하면 좋겠다. list의 indexing에서 list의 크기를 넘어가는 숫자로 indexing하면 에러가 발생함을 확인했다.
dict도 마찬가지로 존재하지 않는 key로 value를 찾으면 에러가 발생한다.
d = {'a': 1, 'b': 2}
print(d['z']) # !!! 'z'라는 키는 존재하지 않는다.
KeyError: 'z'
이 상황의 문제점은 이 에러가 발생하면 이대로 프로그램이 죽어버린다는 것이다. 때로는 프로그램이 죽지 않고, 호출하는 key가 없으면 대신 기본값을 반환하는 코드를 짜고 싶을 수도 있다. 이럴 때 dict.get 메소드가 유용하다.
dict.get은 두 개의 원소를 순서대로 받는다.
- dict에 있는지 확인할 key
- key가 없을 경우 대신 반환할 기본값
d = {'a': 1, 'b': 2, 'c': 3}
# 1. key가 있을 때
print(d.get('a', 0))
print(d.get('b', 0))
print('-' * 10)
# 2. key가 없을 때
print(d.get('aaaaaaaaaa', 0))
print(d.get('z', 100))
1
2
----------
0
100
get 메소드의 첫 번째 인자, 즉 찾고자 하는 key가 dict 내에 존재할 때는 일반 indexing과 같이(d[‘a’] 등) 단순히 key에 대응되는 value를 반환한다. 첫 번째 부분에서 확인할 수 있다.
반면 dict 내에 찾는 key가 없다면 두 번째 인자로 설정했던 기본값이 반환되게 된다. 위의 예제에서 d 라는 dict에는 ‘aaa…’, ‘z’ 같은 key가 존재하지 않는다. 일반적인 indexing이라면 에러가 났을 것이다. 하지만 get 메소드는 에러를 반환하는 대신 두 번째 인자로 지정한 기본값을 반환한다. 이런 동작은 key가 없다는 이유만으로 프로그램이 죽는 불상사를 피할 수 있어 좀 더 강건한(robust) 프로그램을 작성하는 데 좋다. 이 메소드는 유용하니 기억하고 있도록 하자.
6.5. 예제
dict는 활용할 수 있는 예제가 참 많다. 이중 바로 떠오른 것을 구현해보자. 바로 ‘영어 문장에서 각 알파벳의 빈도수 세기’이다. 가령 ‘a’부터 ‘z’까지를 key로 하고, value는 각 글자가 문장에서 등장한 횟수로 하는 것이다. 이때 문제는 정의하기 나름인데, 등장하지 않은 글자는(value가 0인 경우는) 세지 않고, 대소문자 모두 소문자로 통일해서 세는 것으로 한다. 알파벳이 아닌 구두문자 등은 생략한다.
이 문제는 dict로 해결하기 매우 좋은 문제다. 바로 위에서 살펴본 dict.get을 통해 해결할 수 있는 고전적인 문제랄까? 후훗..
sentence = "I'm a boy, you're a girl"
counter = {} # dict 선언
for c in sentence:
if c.isalpha():
c = c.lower()
counter[c] = counter.get(c, 0) + 1
print(counter)
{'i': 2, 'm': 1, 'a': 2, 'b': 1, 'o': 2, 'y': 2, 'u': 1, 'r': 2, 'e': 1, 'g': 1, 'l': 1}
고급진 영어 문장을 준비한 뒤 빈도를 셀 counter dict를 만들었다. 처음에는 당연히 빈 상태이다. 이제 문장을 한 글자씩 순회하는데 str.isalpha 메소드는 글자가 영어 알파벳인지 판별하는 메소드다. 따라서 글자가 알파벳일 경우 글자를 str.lower 메소드로 소문자화한다.
다음이 핵심으로 counter 의 c key에 해당하는 value를 할당 또는 재할당한다. 이때 dict.get으로 해당 key에 대응하는 value, 즉 빈도수가 있는지 확인한다. counter 에 등록되지 않은, 처음 등장하는 글자일 경우 에러 대신 0이 반환되기 때문에 빈도수는 1이 정상적으로 찍힌다. 만약 기존에 존재하는 글자일 경우 기존값에 1만 추가된 값이 재할당될 것이다. dict.get의 동작방식을 그대로 활용한 것이다.
사실 dict를 사용해 만들 수 있는 예제는 더 많은데 현재 포스트의 양이 너무 많아져서 여기까지 하겠다. 하지만 실망하지 말자. 앞으로 수많은 알고리즘에서 dict를 만나 괴롭힘을 당할 것이다. 마지막으로 위 내용을 정리하자.
7. 비교 & 정리
파이썬에는 네 가지의 핵심적인 내장 자료구조가 있는데 list, tuple, set, dict가 그것이다. list와 tuple은 속한 데이터들을 일렬로 세워 번호를 매긴 자료구조로 이것을 이용해 해당 원소의 위치 번호로 원소를 구하는 indexing이 가능하다는 중요한 특징이 있었다. 이때 현대적인 프로그래밍 언어에서는 첫 번째 원소의 인덱스는 1이 아닌 0에서 시작한다.
list는 크기와 값이 변할 수 있는 가변적인 자료구조로 따라서 list.append, list.pop 등의 메소드 등을 통해 원소를 추가, 삭제할 수 있었다. 그렇기 때문에 유용하고 tuple에 비해 자주 쓰인다. tuple은 반대로 한 번 값을 할당하면 어떤 식으로든 변경할 수 없다는 특징이 있어 list에 비해 활용도가 떨어진다. 보통 tuple로 할 수 있는 모든 일은 list로도 할 수 있기 때문에, 다른 말로 list가 tuple의 상위호환이기 때문에 list만으로 많은 작업을 할 수 있다.
set은 수학의 집합의 명세를 그대로 구현한 자료구조로 수학의 집합의 특징을 그대로 받는다. set에서는 같은 원소의 중복이 불가능하고 수학에서 정의하는 차집합, 교집합, 합집합이 구현되어 있다. 이때의 차집합, 합집합 등은 사칙연산의 빼기, 더하기와는 다르기 때문에 list와는 다른 활용방도를 찾아봄직 하다.
dict는 key-value 쌍을 담는 자료구조로 key를 통해 value에 접근하는 구조를 갖고 있다. 마치 금고와 같아서 열쇠(key)를 통해 금고를 열면 그에 맞는 보상(value)이 주어지는 것과 유사하다. dict는 매우 유용해서 C++ 등의 언어에서도 다른 이름의 비슷한 자료구조를 지원하는 등 사용처가 많다. 그래서 잘 사용하면 좋다.
마지막으로 이 네 가지 자료구조의 특징을 표로 한 번 정리해보자.
| 특징 | list | tuple | set | dict |
|---|---|---|---|---|
| 정수 indexing 가능 여부 | O | O | X | X |
| 원소 변경 가능 여부 | O | X | O | O |
| 원소 중복 가능 여부 | O | O | X | key는 불가, value는 가능 |
| 생성 시 사용하는 기호 | [] |
() |
{} |
{} |
| 핵심 메소드 | append, pop, sort 등 | count, index 등 | add, union, intersection 등 | get, values, items 등 |
| 기타 특징 | 타 언어의 Array에 해당하는 매우 기본적이고 중요한 자료구조 | 쓸모없는 것처럼 적었지만 사실 파이썬 내부적으로는 좀 더 쓰임새가 있음 | 수학적 집합 연산이 그대로 구현되어 있어 때때로 유용(차집합 등) | 좀 있어 보이는 표현으로는 연관배열(Associative array)이라는 말로 사람들 현혹 가능 |
8. 마치며
아… 또 1000줄을 넘기고 말았다. 기본적인 자료구조를 설명할 예정이었고, 나름 핵심만 간추린다고 간추렸는데 분량 조절에 실패하고 말았다. 들인 시간과 정성이 포스트의 상품성을 결정짓지 않는다는 지난 교훈을 돌이켜봤을 때 데잇걸즈 분들에게 외면 받는 것은 아닌지 모르겠다. 그러면 조금 슬플 것 같다.
말은 그렇게 했지만 데잇걸즈 분들을 위해서가 아니더라도 여행을 앞두고 꼭 써야했다. 마지막 포스트로부터 10일이 지났기 때문이다. 이번 8월에는 포스트를 3개밖에 못했다. 대체 뭘 한 것인지. 9월 달에는 프로젝트를 조금 더 진행할 예정이다. 따라서 9월에는 프로젝트와 관련해서 공부한 내용을 정리하지 않을까 싶은데 모르겠다.
이 포스트가 파이썬의 핵심 내장 자료구조 네 가지를 이해하는 데 조금이라도 도움이 된다면 더는 바랄 나위가 없겠다. 어땠는지 모르겠습니다. 지식은 물질과 다르게 나눌수록 커지니까 같이 나아갑시다.
이상 포스트를 마칩니다.