
논문을 통한 REST에 대한 고찰
목차
- 들어가며
- 로이 필딩과 REST
- REST의 배경과 제약
- REST의 의미
- RESTful API
- 자료 출처
1. 들어가며
오늘 포스트는 REST에 대해서이다. 이 REST가 지금까지 작성한 포스트 중에서 제일 어려웠다. 그 이유는 REST가 무엇인지에 대해 ‘딱 이거다’ 싶은 정의가 없다. 그러니까 구체적인 Syntax가 없어서 REST가 무엇인지에 대한 해석이 블로그마다 조금씩 다르고 그 해석이라는 것도(대부분은 어디서 퍼온 것일텐데) 권위가 있는 대상인지 의심스럽다. 그래서 너무 감이 안 잡혀서 공부하기가 싫었다.
그래서 내가 선택한 방식은 정공법이다. REST를 제안한 Roy Fielding(이하 “로이 필딩”)의 박사 논문 “Architectural Styles and the Design of Network-based Software Architectures“에서 REST를 언급한 5, 6장을 읽고 무슨 느낌인지는 알게 됐다.
그래서 이번 포스트는 REST이 무엇인지 논문을 통해 그 느낌을 파악하려고 한다. 먼저 로이 필딩이 뭐하는 사람인지 살펴본다. 이 사람의 이력이 REST와 깊은 관련이 있다. 그리고 그의 논문에 있는 중요한 문장들을 번역하고 그에 대한 내 주석을 다는 방식으로 진행한다. 이렇게라도 하지 않으면 REST가 뭔지 블로그들을 뒤져가지고서는 감을 잡기 어렵거나 단순히 URL 작성 규칙으로 알게 될 수 있다.
그리고 그의 논문에서는 REST API의 구체적인 문법은 다루지 않는다.(그래서 내가 그것들을 다룬 포스트들이 의심이 된다) 그렇기에 RESTful한 API를 만들기 위한 규칙은 논문에서의 내용을 기반으로 조금만 추론해보도록 하겠다.
2. 로이 필딩과 REST

사실 REST를 이해하기 위한 그의 이력은 논문에서 소개한 웹에 대한 자신의 이력을 살펴보면 된다.
그가 REST를 개발할 때는 웹이 폭발적으로 성장하고 있었지만 어떤 웹 전체를 꿰뚫는 ‘표준’이라는 개념이 미비했던 때로 표준을 만들기 위한 여러 움직임이 있었다. 그의 표현에 따르면 그 당시에는 “웹의 구조를 서술하는 비공식 문서들과 두 개의 소개 형식의 논문 등이 있었지만 실제 웹 구현이 너무 빨라 이미 시대에 뒤떨어진(out-dated) 경우가 많았다” 또 “그 당시 이미 캐시와 프록시 등이 웹에는 존재했지만 이에 대해 인식하는 표준은 없다시피 했다.“ 그렇기에 웹에 대한 새로운 표준, 또는 표준의 확장이 꼭 필요했다.
그래서 팀 버너스 리가 이끄는 W3C와 IETF 같은 곳에서 표준화 작업에 본격적으로 착수했다. 그는 웹 소프트웨어를 개발했던 경험 덕분에 상대적 URL의 사양, HTTP 1.0의 사양, HTTP 1.1의 초기 주요 설계자, 마지막으로 URI의 generic 문법 표준의 사양 개정 등 웹 표준화에 상당한 기여를 했다. REST가 처음 개발된 것은 1994년 10월부터 1995년 8월 사이로 HTTP 1.0, 1.1의 개념을 소통하기 위해서였다고 한다. REST가 웹, HTTP와 큰 관련이 있는 것은 이 때문이다.
3. REST의 배경과 제약
REST을 개발하게 된 동기는 웹이 어떻게 동작해야 하는지에 대한 구조적 모델을 만들어서 웹 프로토콜 표준을 위한 guiding framework 역할을 하기 위함이었다.
이 말은 앞서 그의 이력에 소개한 것과 일맥상통한다. 인터넷 네트워크를 생각해보면 HTTP뿐만 아니라 TCP/IP 프로토콜 스택을 사용하는 어플리케이션 프로토콜이 많이 있다. 이것과 마찬가지로, 웹 프로토콜을 사용하는 수많은 웹 어플리케이션과 프로토콜이 존재한다. 웹 자체에 대한 표준이 미비하면 그것을 사용하는 어플리케이션마다 사양이나 인터페이스가 천차만별일 수 있기 때문에 REST가 향후 웹과 관련된 어플리케이션, 프로토콜의 일관성을 위한 guiding framework가 되기를 바랬다.
REST는 분산 하이퍼미디어 시스템의 구조화 스타일을 다룬다. REST는 여러 네트워크 기반 구조화 스타일을 접목해 만들었으며 동일한 인터페이스를 위해 추가적인 제약을 추가했다.
REST는 분산 하이퍼미디어 시스템의 구조화 스타일에 대해 다룬다. ‘분산 하이퍼미디어 시스템’은 웹을 지칭한다. 인터넷 자원은 전세계에 분산되어 있으며 HTTP를 사용하는 웹은 초창기 연구자들의 단순 문서 공유의 목적에서 크게 벗어난 하이피미디어 시스템이 되었다. REST는 이런 시스템을 구조화할 때 지켜야 할 스타일을 정의한다.
그리고 현대의 웹 프로토콜 HTTP를 사용하는 웹 어플리케이션도 (웹보다 작은) 분산 하이퍼미디어 시스템이라고 할 수 있기 때문에(유투브로 우리는 줄글이 아닌 동영상을 본다) 이 스타일을 적용할 수 있는 것이다.
또 로이 필딩은 REST는 성경의 십계명 받아적듯이 완전 무에서 태어난 것이 아님을 밝히고 있다. 웹이 지배적인 어플리케이션이기는 하지만 인터넷에는 다른 여러 프로토콜의 네트워크도 많이 펼쳐져 있다. 그는 여러 네트워크의 구조화 스타일을 참고해서 웹과 같은 분산 하이퍼미디어 프로토콜에 적합한 표준을 이끌어냈다.
그리고 그것을 위해 여러 제약(Constraint)을 만들었다. 이 제약을 생각해보자. 그는 여러 네트워크를 참조해서 웹에 적합한 구조화 스타일을 만들었다고 밝히고 있다. 그러니까 그가 처음에 만든 스타일은 여러 네트워크의 장점을 살린 원형의, 그의 표현을 빌리자면 generic한 찰흙같은 시스템에 적합한 스타일이다. 이 스타일을 웹에 맞게 만들어나가기 위해 현대적인 웹의 특징들을 시스템의 제약으로 삼음으로써, generic 했던 구조를 웹에 적합한 구조로 만들어 스타일을 정의할 수 있었다. 그 제약들은 다음과 같다.
- 클라이언트-서버
- 클라이언트와 서버를 분리하고 인터페이스로만 소통할 수 있게 해서 유저는 멀티플랫폼의 이동이 가능해지고 서버의 컴포넌트 를 단순화해 확장성을 향상. 각 컴포넌트들은 독립적으로 진화할 수 있다.
- 가령 클라이언트 환경은 단순히 브라우저의 문제뿐 아니라 모바일, 데스크탑, 랩탑 등의 다양한 환경으로 발산했는데 서버와 클라이언트단은 분리되어 서버는 이런 클라이언트의 문제를 고려할 필요가 없어졌다.
- Stateless(무상태성)
- HTTP는 원래 무상태 프로토콜. 상태가 필요하면 상태정보를(가령 세션) 서버에 두지 말고 클라이언트에 의존할 것. 이 제약은 가시성, 책임성, 확장성의 효과를 불러온다. 가시성은 시스템이 요청에 대해 그 요청 메시지 이상 고민할 필요가 없어서이고, 책임성은 부분 시스템 실패로부터 회복하는 작업을 쉽게 해주며, 확장성은 서버가 요청간 상태정보를 저장할 필요가 없어 자원을 쉽게 해제할 수 있어서이다.
- 무상태는 단점도 있다. 상태를 저장하지 않기 때문에 요청마다에 데이터를 반복적으로 보내야 할 수도 있어 성능의 문제가 있을 수 있다. 또 상태를 클라이언트에 두면 어플리케이션이 여러 클라이언트 환경에 종속적이 되기 때문에 서버가 어플리케이션에 대한 완전한 제어를 할 수 없다.
- Cache
- 네트워크 성능을 향상시키는 대표적인 방법이 cache이고 웹은 클라이언트부터 시작해서 cache를 정말 많이 사용한다. 그래서 Cache 제약을 둔다. 이 말은 응답 메시지의 데이터에 캐시 가능한지, 가능하지 않은지 등에 대해 언급해야 한다. 응답 메시지가 캐시 가능하면 클라이언트 캐시는 그 메시지를 재사용할 권리가 생긴다.
- 이의 장점은 네트워크 성능으로 이는 명확하다. 트레이드오프는 캐시가 stale한 정보를 담고 있어 최신의 상태를 담보하지 못할 수 있다는 것
- HTTP 응답 메시지 헤더에서 데이터의 캐시 사용성에 대해 서술하는 Cache-control 헤더가 있는 것이 대표적이다.
여기에 더헤 몇 가지 제약이 더 있다.
웹을 구현하는 개발자들은 이미 웹의 초창기 디자인을 넘어섰다. 정적인 문서 대신에 요청은 동적으로 생성된 응답이나 서버사이드 스크립트 등도 확인할 수 있게 되었다. 웹의 컴포넌트들이 신뢰할 수 있게 소통하기 위해서는 프로토콜의 확장이 필요하고 현대적인 웹 구조를 지도하기 위해 몇 가지 제약이 추가됐다.
- 공통된 인터페이스
- REST를 다른 네트워크 기반 구조화 스타일와 차별화하는 중심적인 특징은 컴포넌트간 공통된 인터페이스의 강조다. 소프트웨어 공학의 ‘generality’를 컴포넌트 인터페이스에 적용함으로써 전체 시스템 구조가 단순해지고 상호작용간 가시성이 향상되었다. 구현은 서비스와 결합해지되어(decoupled) 독립적인 진화가 가능해졌다.
- 단점도 물론 있다. 공통된 인터페이스는 효율을 떨어뜨린다. 어플리케이션 특화된 인터페이스를 사용하지 않기 때문.
- REST 인터페이스는 ‘large-grain’한(‘대용량’의 뜻인 것 같다) 하이퍼미디어 데이터 전송을 효율화하기를 꾀한다. 다른 시스템에는 적용되지 않을 것
- 공통된 인터페이스를 유지하기 위해 REST는 컴포넌트간 행동을 제약하는 4가지 추가적인 제약이 필요하다. identification of resources, manipulation of resources through representations, self-descriptive messages, hypermedia as the engine of application state
결국 REST가 꿈꾸는 인터페이스는 HTTP와 URI을 통해 웹의 모든 컴포넌트들이 상호작용할 수 있는 generic한 인터페이스다.
- Layered system
- 인터넷 단위의 요구사항을 위한 행동을 향상하기 위해 이 제약을 도입. 이 제약은 OSI 7계층 모델처럼 컴포넌트가 인접한 컴포넌트 의외의 영역을 “볼 수 없는 것처럼”한다. 이를 통해 전체 시스템 복잡도에 한계를 주고 독립성을 증진한다. 레이어는 레거시 서비스를 감싸서 새 서비스를 레거시 클라이언트로부터 보호할 수 있다.
- Code-on-demand
- REST는 애플렛(Applet)이나 스크립트의 형태의 코드를 다운로드하고 실행해서 클라이언트 기능성이 확장되는 것을 허용한다.
4. REST의 의미
REST는 ‘REpresentational State Transfer’의 약자이다. 이 단어가 아리송해서 저마다의 많은 해석이 있다. 하지만 그의 논문을 통해 이 의미를 직간접적으로 이해할 수 있는데 Representational과 State transfer을 나눠서 생각해보자. 먼저 ‘State transfer’의미는 논문에서 REST의 뜻을 설명하는 부분에서 파악할 수 있다.
이름 ‘REpresentational State Transfer’은 잘 작동하는 웹 어플리케이션이 어떻게 동작하는지를 이미지화하려고 했는데: 웹 페이지들의 네트워크를 가상의 상태머신으로 두고 유저가 링크를 선택해서 어플리케이션을 진행시키면 상태 전이가 일어나서 다음 페이지로 가게 된다.
REST의 이름에 대해 설명한다. 그는 웹 페이지의 네트워크를 하나의 가상 상태머신으로 봤다. 한 상태머신은 유한한 상태 집합을 갖고 그 중 한 시점에 한 상태를 지닐 수 있다. 네트워크 내에서 한 웹 페이지를 한 ‘상태’로 표현했다. 그래서 유저가 링크를 선택하면 상태 전이(state transfer)가 발생해서 다음 상태(페이지)로 넘어가게 된다고 본 것이다.
이는 다른 블로그들에서 한 페이지가 CRUD를 통해 여러 상태를 넘나든다고 하는 것과는 대조적이다. 그래서 블로그들을 못 믿겠다.
이제 ‘Representaional’의 의미를 살펴보자. 이 의미도 아리송해서 어떤 블로그는 ‘대표의’ 라는 뜻으로 해석했다. 그러니까 REST를 ‘대표적인 상태 전달’이라고 해석했는데 이게 대체 무슨 말인지…
이 ‘Representation’은 ‘대표’가 아닌 ‘표현’으로 봐야한다. 이 단어는 그의 논문에서 매우 중요한 위치를 차지하는데 그 의미를 살펴보자.
먼저 REST에서의 Resource(이하 “자원”)에 대해 이해해야 한다. 우리는 흔히 서버가 제공하는 모든 데이터 자체를 ‘자원’이라고 인식하는 경향이 있다. 한 URL이 하나의 자원을 의미한다고 보는 것인데 REST에서는 이런 해석은 틀렸다. 물론 초기 웹에서는 URI를 문서 식별자로 정의해서 관리자들은 이 식별자를 네트워크 상에서의 문서의 위치로 정의하라고 지시 받았다. 웹 프로토콜은 URI를 통해 그 문서들을 ‘Retrieve’할 수 있었다. 하지만 이런 관점은 몇 가지 단점이 있다.
- 이 의미는 문서가 전송될 때, 내용이 바뀌면(가령 ‘PUT’이나 ‘POST’ 메소드를 통해) 식별자도 바뀌어야 할 것 같은 느낌을 준다.
- 문서보다는 서비스에 더 가까운 식별자도 있다.
- 식별자가 주소나 정보보다는 오직 네이밍만을 위해 쓰이거나 문서가 존재하지 않을 때도 있다.
REST에서 자원은 실제 가치나 문서, 정보 그 자체가 아니라 그에 대한 식별할 수 있는 ‘의미’가 된다. 이런 해석을 왜 하는 것일까? 그것은 웹이 하이퍼미디어 네트워크라는 것과 관련이 있다. 하이퍼미디어에서는 일반 평문 문서뿐만 아니라 구조화된 HTML, JSON 문서, 이미지, 동영상 등의 다양한 형식의 데이터를 허용한다. 우리는 일반적으로 이렇게 정보와 형식을 묶어서 하나의 파일 등으로, 통으로 인식한다. 하지만 로이 필딩은 다르게 생각했다. 같은 내용의 데이터를 XML, HTML, JSON의 형식에 맞게 따로 작성할 수 있듯이, 정보를 뜻하는 자원과 표현하는 양식(Representation)을 분리한 것이다. 웹에서 활동하는 컴포넌트(서버, 프록시 등을 의미한다)들은 자원을 전송하는 것이 아니라 자원의 표현을 전송해서 소통하는 것이다. 그때 자원의 표현은 표준화된 데이터 타입 집합 중 수령자의 능력이나 기호에 기반하거나 자원의 특성에 따라 동적으로 선택된 포맷이 선택된다. HTTP 클라이언트 헤더에서 ‘Accept’를 통해 받고자 하는 자원의 표현을 지정할 수 있는 것이 대표적이다. 서버에서 전송된 자원의 표현은 원 출처와 같은 표현일 수도 있지만 다른 표현일 수도 있는데, 이는 인터페이스 뒤에 가려져 알 수 없다.
REST 컴포넌트들은 자원에 표현을 써서 자원의 현재 또는 의도된 상태를 포착하고 이 표현을 다른 컴포넌트에 전송한다. 표현은 바이트의 연속과 그 표현을 설명하는 메타데이터를 포함한다. 조금 부정확하지만 자주 쓰이는 표현의 다른 이름은 파일, 문서, HTTP 메시지 객체, 인스턴스, 변수 등이 있다. 그리고 그 표현의 포맷을 ‘Media type’이라고 한다.(!!)
REST는 URI 표준을 ‘자원’으로 정의하고 그 자원을 표현으로 조작한다.
REST의 관점에서 클라이언트의 요청과 서버의 응답을 표현하면 다음과 같다.
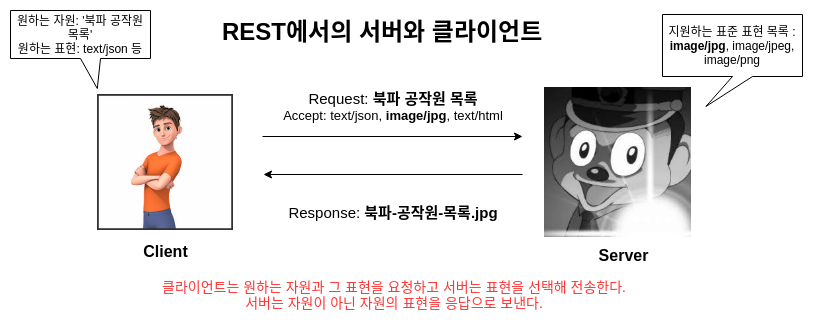
이제 REST의 한국어 의미를 내가 다시 재정의해보겠다.
한 웹 네트워크는 전이 가능한 여러 상태를 갖는데 이때 유저가 링크를 클릭하면 URI로 매핑된 그 상태로 전이한다.(State Transfer). 이때 그 상태 정보(페이지)는 표현에 의해 조작되어 또는 전처리되어(Representational) 전송된다.
5. RESTful API
사실 REST를 공부하라는 의미는 REST의 역사나 철학을 공부하라는 의미가 아니라 REST한 인터페이스(API)를 만들라는 의미로 쓰이는 것 같다. REST API는 REST의 규칙을 잘 이해하고 실현한, 다시 말해 RESTful한 API를 말한다. 하나 꼭 당부하자면, REST를 부디 ‘URL을 만드는 규칙’ 정도로 이해하지 말 것을 바란다. REST는 웹 프로토콜이나 어플리케이션의 구조화 스타일이다. 우리가 만약 카카오톡을 성능에서 구더기로 보이게 할 정도의 메신저를 만든다면 그 메신저만을 위한 네트워크 프로토콜이 필요할 것이다. ‘이 프로토콜을 REST하게 만들자’가 내가 생각할 때 로이 필딩이 생각한 REST의 역할이다. 하지만 그보다는 어플리케이션의 URL을 REST하게 만드는 작업이 우리에게는 더 현실적이기 때문에 우리는 이를 공부한다. 하지만 ‘이게 REST다 라고 이해해서는 안 된다’가 내가 논문을 읽고 느낀 바다. 꼭 짚고 넘어간다.
REST API 규칙에 대해 추론할 수 있는 몇 가지 언급은 논문에서 찾을 수 있다.
REST는 분산 하이퍼미디어 시스템 내의 구조화 요소들에 대한 추상이다. REST는 컴포넌트 구현이나 프로토콜 문법은 무시하고 컴포넌트의 역할, 컴포넌트간 소통에 대한 제약, 중요 데이터 요소에 대한 해석에 관심이 있다.
먼저 이거. 그의 논문에서는 ‘URL은 어떻게 작성해야 한다’는 식의 구체적인 언급은 한 마디도 없다. 그래서 사실 내가 적는 내용이 조금은 못 미덥다. 구체적이지 않기 때문에 REST가 무엇인지에 대한 생각이 사람마다 조금씩 다를 수 있는 것이다.
그래서 이 포스트에서는 구체적인 API 규칙은 살펴보지 않겠다. 관련된 포스트가 많으니 참고하길 바란다.(여기) 작성 잘 해놓으셨다. 대신 논문에서 소개된, 그리고 로이 필딩이 이후에 작성한 REST API에 대한 언급에서 단서를 찾도록 한다. 이 부분을 읽고 다른 누군가 써놓은 규칙을 살펴보면 일맥상통함이 분명 있다. 그것을 발견하는 것이 이 포스트의 목적이기도 하다.
REST에서의 자원의 정의는 단순한 전제로 시작한다: 식별자는 가능한 변하지 말아야 한다. 한 자원에 대한 참조(링크)를 여러 번 접근해서 정보의 내용이나 결과가 바뀔지라도 참조는 정적이어야 한다. REST는 ‘자원’이 확인하고자 하는 것에 대한 의미(semantic)라고 정의하며 실제 문서와 같은 가치, 정보라고 보지 않는다. 그렇기 때문에 가치, 정보가 변하거나, 읽히거나 심지어 삭제되어도 참조는 불변을 유지할 수 있다.
이건 좀 크다. 이것은 시사하는 바가 있는데 한 자원이 읽히거나(READ), 생성되거나(POST), 업데이트되거나(PUT), 삭제(DELETE)되어도 URL은 자원 그 자체가 아니라 의미 또는 참조이기 때문에 변하지 않는다. 이는 이후 내용에 큰 통찰을 준다.
로이 필딩이 2008년 10월 20일에 작성한 ‘REST APIs must be hypertext-driven’라는 포스트가 있다. 여기서 그는 사람들이 모든 HTTP 기반 인터페이스를 REST라고 부르는 것에 좌절하고 있다면서 REST 스타일에서 ‘hyptertext’는 앞서 이야기한 ‘제약’이라고 말하고 있다. 다시 말해 어플리케이션 상태가 하이퍼텍스트 기반이 아니라면 RESTful하지 않다고 말한다.
REST 규칙을 설명하고 있는 다른 많은 블로그들에서 API는 실제 웹 페이지에서 링크를 타고 내려가듯이 계층구조를 이루어야 한다는 말이 이 ‘hyptertext-driven’과 일맥상통하는 듯하다. Hypertext는 웹의 중요한 성질 중 하나로 링크를 통해 다른 페이지(상태)로 전이할 수 있게 한다. 이때 링크를 타고 넘어가면 페이지와 페이지를 잇는 트리를 만들 수 있는데 트리는 대표적인 계층을 표현하는 자료구조다. 이 페이지 링크 트리를 타고 넘어가듯이 URL을 작성하라는 것이 곧 ‘hyptertext-driven’이라고 생각되었다.
예를 들어 313(내 생일이다)을 아이디로 하는 유저의 정보를 담는 상태를 ‘~/foobar/users/313’이라고 하자. 이 페이지는 해당 유저에 관한 많은 정보와 연결될 수 있는데(Edge) 가령 유저가 그동안 작성했던 포스트들을 담은 상태로 넘어갈 수 있다고 하자. 그때 URL을 ‘~/foobar/users/313/posts’와 같이 작성하면 유저 페이지에서 ‘작성했던 포스트’ 페이지로 링크(hypertext)를 통해 이동한 것을 URL 계층구조로 표현할 수 있다.
6. 마치며
철저히 논문에 근거한 REST를 살펴보았다. 로이 필딩은 웹 표준화에 기여한 사람으로 웹을 기반으로 해서 앞으로 만들어질 웹 어플리케이션과 웹 프로토콜들을 설계할 수 있는 프레임워크를 만들려고 했고 그 결과가 바로 REST이다. REST는 여러 분산형 하이퍼미디어 시스템을 참고해서 일반적인 원형 시스템을 만든 다음, 여러 제약들을 추가해서 웹에 적합한 시스템 구조를 구성했다. REST한 API는 이 제약들을 모두 문제없이 따라야 한다.
REST는 기존의 URL을 자원 그 자체로 보는 시야에서 벗어나서 URI는 자원을 식별하는 ‘의미’로 보고, 자원은 실제 정보와 그것을 담는 ‘표현’으로 구분함으로써 하이퍼미디어 시대에서 다양한 미디어타입을 지원함을 설명했다. 서버에서 클라이언트로는 자원이 아닌 자원의 표현이 전송되며 이렇게 링크를 통해 페이지를 옮기는 것은 곧 상태를 전이하는 것이 된다.
REST에 대해 처음 공부하면 나처럼 위와 같은 내용을 알지 못하고서는 도무지 이해를 할 수 없게 써놓은 포스트들이 꽤 많다. 차라리 그러면 이 포스트가 더 도움이 될 수도 있겠다. 내용 그 자체에는 썩 만족스럽지 않다. 뭔가 REST가 내 머리속에 관념적인 철학으로 자리잡았고, 아직도 구체적인 규칙으로서는 다가오지 않는다. 그리고 어디 적혀 있는 세세한 규칙들은 솔직히 못 믿겠다. 필요할 때만 찾아보면서 적용할 생각이다. 그런 규칙에 목매는 것은 파이썬의 PEP에 목매는 것과 비슷한데 생각해보면 내가 거기에 집착하고 있는 것이 모순되는 것 같기도 하다.
이상 포스트를 마칩니다.
7. 자료 출처
- Architectural Styles and the Design of Network-based Software Architectures, Ch 5,6
- Codecademy Articles: What is REST?
- [Network] REST란? REST API란? RESTful이란?
- REST APIs must be hyptertext-driven
- Wikipedia: REST